Grumpy chronicles: The question of utils
This is an ongoing mini-series of lessons learned from writing a tiny blog engine in Clojure. Code we will be discussing today.
The problem
Every project has a utils namespace. Usually, it’s a huge single namespace with all the tiny code bits that need to be used from more than one place in the project.
As the project starts to grow, a single namespace becomes hard to keep organized. You might notice that functions are in more or less random order, related things are not necessarily be grouped together. That lowers discoverability and reuse, the main reason utils exist in the first place.
Mixed Clojure/Script projects have another issue: many of the utils only make sense on a single platform, while others need to be cross-compiled. Unfortunately, you can’t create utils.clj, utils.cljs AND utils.cljc all at the same time. And keeping everything in utils.cljc would mean putting #?(:clj) or #?(:cljs) around 2/3 of the functions.
The solution
I split utils into a family of namespaces grouped by domain. E.g. numbers — one namespace, collections — another, time, urls, files, etc. Grumpy is a small project (<2000 LoC), yet we already have 17 such libraries:
└── core
├── coll.cljc
├── config.clj
├── files.clj
├── fragments.cljc
├── jobs.clj
├── log.cljc
├── macros.clj
├── macros.cljs
├── mime.cljc
├── posts.clj
├── routes.clj
├── time.clj
├── transit.clj
├── transit.cljs
├── url.cljc
├── web.clj
└── xml.cljThis is a joy to work with. If I need to do something with a file, I go to grumpy.core.files. If what I need is not there, I create a function right there, where it belongs. And it feels good: things stay neatly organized, writing new code does not increase a tech debt. Each namespace is essentially a small library: useful, focused, comprehensible, with clear mission and scope, no more and no less. If everybody loves good reusable libraries, why not organize your own project like it?
And don’t worry if some namespaces start small. For example, grumpy.core.log is just a single one-line function:
(defn log [& args]
(apply println #?(:clj (time/format-log-inst)) args))What matters is that semantically it’s its own area of responsibility, so it has to go into its own namespace.
It also makes thinking about dependencies somewhat easier. You have a two-part graph: reusable libraries and business code. The bottom half can depend on the top half, but not vice versa. Here’s how it looks in Grumpy right now (arrows means “depends on”):
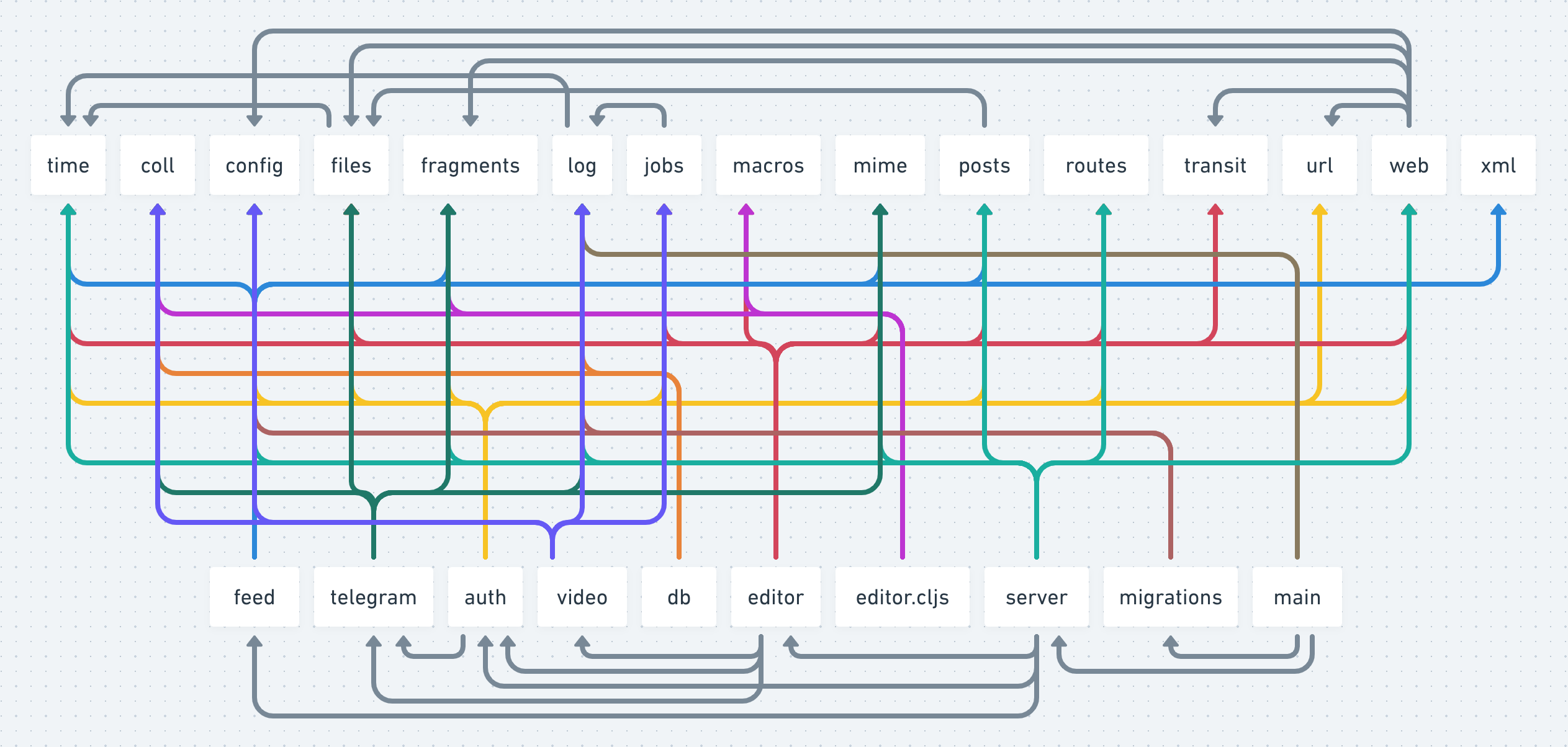
Normally depending on “business” namespaces might be complicated if there are special conditions, how namespaces should be loaded, dependency loops, etc. The utility namespaces are the direct opposite of that. They guarantee not to depend back on “business” code, just like an external library would! If you put your code in the top half, the rest of the project can always reference it with zero effort.
The rule
Single-file utils namespaces are very convenient for people and, just like entropy, they have a tendency to appear almost on their own. You have to take active action to prevent this from happening. I even go as far as declaring it a principle:
A catch-all util namespace is not allowed.
If you want to make a piece of code reusable, figure out to which sub-library, semantically, it should go. This creates a clear point for making a decision, forcing everyone to decide here and now, but in the long run, it will save you a lot of headaches.
