Unofficial guide to Datomic internals
Disclaimer: I do not work for Cognitect and, unfortunately, haven’t seen any source code of Datomic. I just made it through a lot of public talks, docs and google group answers about Datomic. This post is a compilation thereof. Intention is to help others use Datomic more efficiently by understanding what they are doing.
Persistence
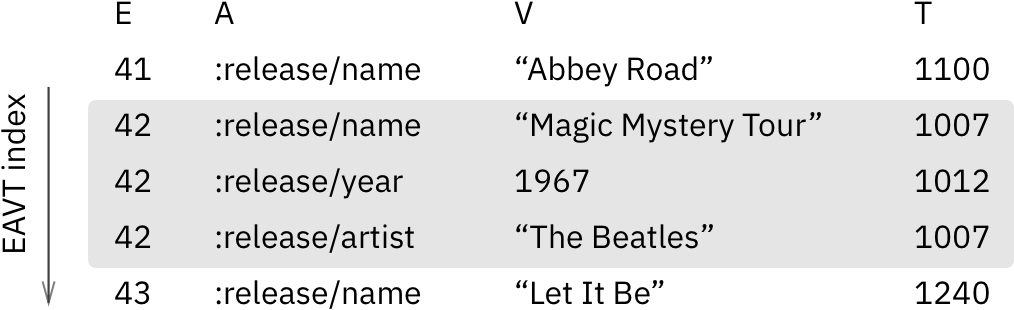
Datomic models all data as 4-tuples (entity, attribute, value, time) called datoms. In “John likes pizza” “John” is an entity, “likes” is an attribute and “pizza” is a value. Everything in Datomic is represented as such simple facts. This simplicity enables Datomic to do more than any relational DB or KV storage can ever afford: to efficiently store and access sparse, irregular, hierarchical, graph data and multi-valued attributes.
Datomic does not manage persistence itself, instead, it outsources storage problems to databases implemented by other people. Data can be kept, at your expense, in DynamoDB, Riak, Infinispan, Couchbase or SQL database.
Storage is used to store segments as binary blobs, similar to how DBs store blocks on file system. It’s basically segment key (UUIDs are used) to segment body mapping, so Datomic requires only two things to be supported by a storage: key-value interface and CAS for updating index root records. Segments are immutable, and, once written, cannot be changed. Re-indexing only writes new segments. This makes consistent reads and immutability possible.
Indexes
There’s no dedicated datom storage; instead, covering indexes are used. This means they contain actual data, not a reference to a place where data can be obtained. Data reads happen directly from index, there’s no other place where data is stored beyond indexes. There’s some redundancy in it, because if а datom ends up in 3 indexes, it’ll be stored 3 times. But it’s partially mitigated.
Indexes are B-tree-like structures: sorted, immutable, persistent, 1,000+ branching factor, custom sort order, fast lookup and range scans, able to be efficiently merged (details unknown). Index trees are shallow, no more than three level deep: root node, directories and segments as leafs.
Elements of index trees are not individual datoms, but segments. Segment is an array of datoms, serialised with Fressian, then compressed with zip. Segment size may be up to ~50 Kb, usually including from
There’re five indexes, they differ in coverage and are named after the sort order used:
- EAVT is for efficient access to the attributes of an entity, similar to primary key lookup in traditional DBs.
- AEVT is for column-style access, to retrieve entities list by a given attribute. Both EAVT and AEVT store every datom.
- VAET is used for navigating relations backwards and stores all datoms with reference attributes. Given VAET, you can not only find out whom John follows (
“John” :follows ?x), but also efficiently lookup who follows John (?x :follows “John”). - AVET provides efficient lookup by value and stores datoms with attributes marked as
uniqueorindexin schema. Attributes of this kind are good for external ids. AVET is the most problematic index in practice, and it’s better if you can manage to put monotonic values in it, or use it sparingly. - Finally, there’s Log index, which stores all datoms sorted by transaction id.
Partitions are just big pre-allocated entity id ranges (242). That way, when you add new entities to one partition, they will not mess up EAVT index segments related to other partitions. They also provide semantic grouping: when querying cities, for example, you will not get random stuff that happened to interleave them just by getting next db-wide sequential id.
Same logic applies to attributes: it’s better to have not a single :name attribute, but use namespaced versions for different entity classes (:city/name, :person/name, :transaction/name, etc.). That way AEVT and AVET index updates will get better locality.
Queries that cannot be covered by index (e.g., filter DB by Tx; or lookup by value of non-indexed attribute) lead to full DB scan and either throw exceptions at you or spend a lot of time “thinking”.
Index internals
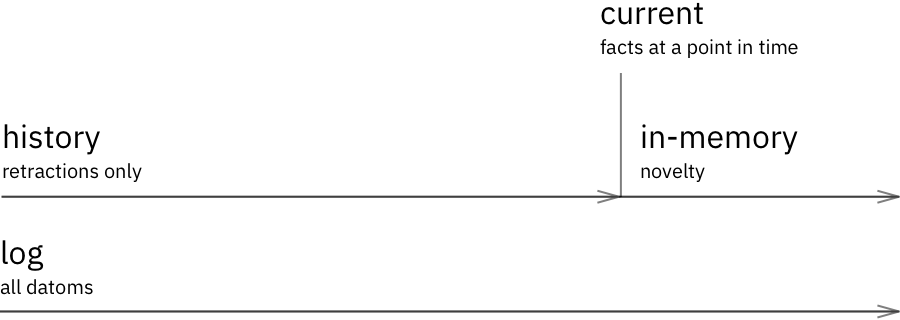
Each index is conceptually a single unit, but (except Log) is technically split into three parts, with different location and usage pattern:
- History part contains datoms that by now have been changed or deleted, so no longer hold true (both initial assertions and subsequent retractions). History is durable and kept in storage.
- Current part contains latest assertions only, facts that are relevant at the moment index was built. If “Mary” gets renamed to “John”, only “John”, as latest true datom, will be included. Current part is durable and is kept in the storage too.
- In-memory part contains both assertions and retractions, is ephemeral and is kept in peers’ and transactor’s memory.
In-memory part acts like a buffer, accumulating novelty between index rebuilds. Newly written data gets written to the Log (hitting storage for write here) and to the in-memory index of transactor. Transactor then propagates that novelty to all peers, ensuring they have the same in-memory index content.
New peers or peers that got disconnected all start with empty in-memory index. They start reading Log from the point where the latest current index was built, populating their in-memory index from that information.
Peer and transactor communication is push-based. Whenever transactor has completed a transaction, it’ll notify all peers immediately, so peers will know about the new data as fast as it’s possible. Peer db call does not communicate with transactor, it returns the latest DB value that the peer has heard of.
Executing queries
Now, we have indexes and want to execute queries over them, right? It is just the time where the ability to efficiently merge persistent trees comes in handy. Queries are never answered from a single index, they always consult two, sometimes three index parts:
- To answer a regular query, current and in-memory parts get merged, giving you an illusion you’re querying the latest version of DB.
- To answer
as-ofquery for moment T, current, in-memory and history parts get merged, and then all data with timestamp after moment T is ignored. Note thatas-ofqueries do not require older versions of current index, they use most recent current index and filter it by time, deducing the previous view of the database. - With
historyAPI call, you get merge result of in-memory, current and history index parts. It will contain all assertions and retractions that have happened during the DB lifetime. You decide what to do with that information. - With recent versions of Datomic, you can also access Log index (
log) which is not very efficient for queries, but can be efficiently asked for a range of transactions between two timestamps.
Re-indexing and garbage collection
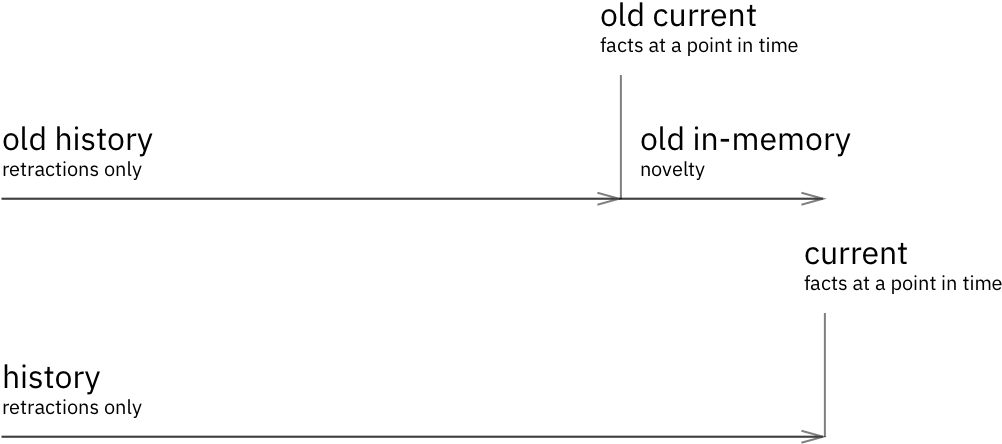
When in-memory index gets too big (memory-index-threshold, e.g. 32 Mb), transactor starts current index re-built. It is done by merging latest current index with in-memory index. Assertions are copied from in-memory to current index, outdated assertions and retractions are copied from in-memory to history. Changes in attributes marked as noHistory are silently dropped. When current/history index rebuild is done, peers and transactor learn about new version of them and drop all in-memory novelty that is now covered by the new indexes.
There’s an API call to force re-indexing, request-index.
All databases obtained from datomic.api/db call always reference the latest current index. Once current index is rebuilt, there’s no way to obtain reference to older versions of it. The data segments that were referenced by older versions of current index, if they were “changed” and therefore not reused by latest version, are now subject to GC.
Garbage segments can be cleaned up, but if some peer is keeping the reference to the DB it obtained long time ago, that DB still may be referencing an old index. In most cases, you get the db, do some processing, and forget about it. But analytics processing or other long-running jobs may violate that pattern. Thus, GC is a manual operation, and is recommended to be run rarely (e.g., once a week). There’s an API call for that, gc-storage. If old index referenced by DB was garbage collected, an equivalent DB version can be obtained by getting latest DB and calling as-of on it.
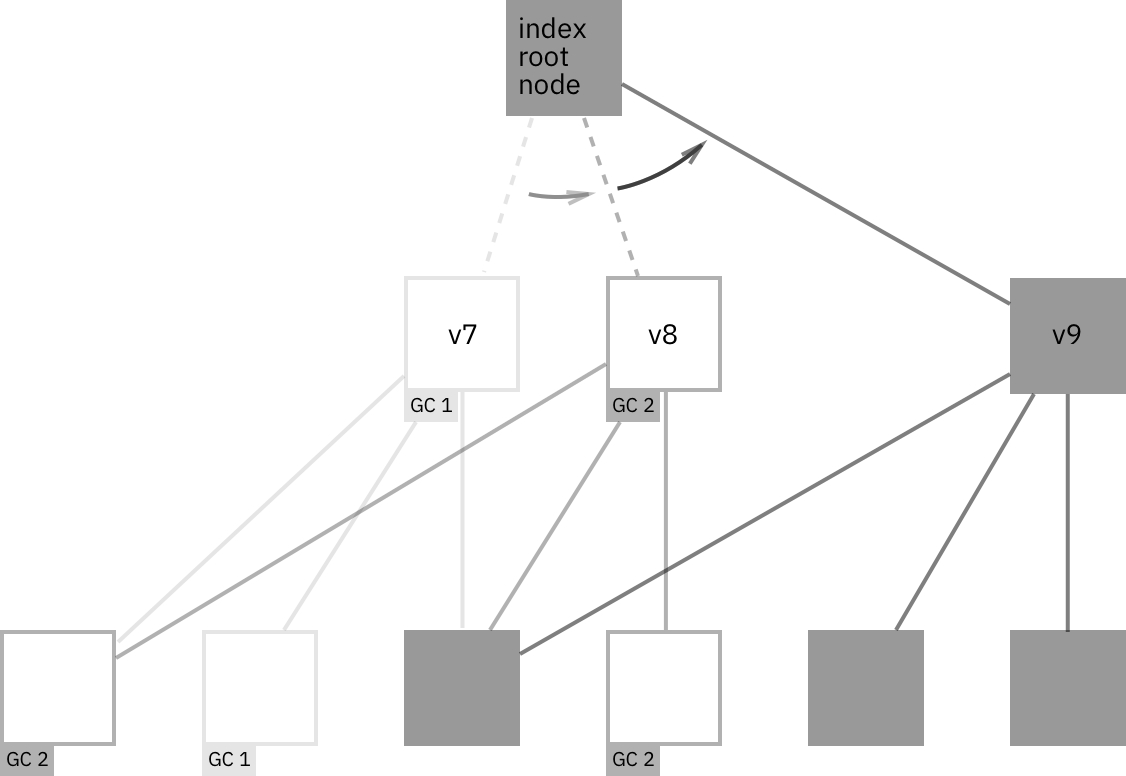
Neither GC nor re-indexing are blocking operations. They both happen in background and do not interrupt normal DB operation in any way.
Laziness
DB value you run queries across contains reference to root index node. Peer then deduces which segments it needs to execute the query, and reaches storage for missing segments. Queries can run across datasets that do not fit in memory (by loading and unloading cached segments during DB scans), but the result of query should fit in memory. Query results are not lazy.
There’s an API for walking indexes directly (datoms and seek-datoms). It’s lazy and can be used when you need to walk big dataset but cannot express your intentions in a query.
Transactor does not participate in queries. Peers with no transactor connection can still do reads from storage. If required segments are already cached, query will be executed without network reads at all.
Caching
Caching helps to keep working set close and warm, reducing latency and storage load.
Since segments are immutable, it’s a no-brainer to cache them — you don’t need to invalidate. Datomic supports memcache for fast external segments cache, and peer library keeps in-memory cache too. In-memory peer segments maintain two types of cache: compressed segments cache (off heap) and uncompressed segments cache (on heap, limited by object-cache-max, e.g. 128m).
Because caching happens at segments level, when you obtain one attribute, you probably also obtain 1,000–20,000 datoms around it. It means you won’t get N+1 select problem if you, say, are reading entity attributes one-by-one. This kind of thing was a big no-no in traditional client-server databases.
In conclusion
Overall, I’m very impressed how simple and elegant underlying structure is. Building blocks are small, but the combination of them is impressive in feature set. There’s almost no tricks and compromises, everything is derived directly from core model. Transactor and peers are doing very different things using the same set of basic primitives. It feels like they’ve built a whole database from tuple, persistent sorted set and communication queue.
