Reinventing Git interface
I have a long love-hate relationship with Git. Despite solving all my problems with version control and having a technically excellent implementation, the whole experience sucks constantly. I’ve tried it all: official CLI, non-official CLIs, gitk, third-party GUIs. It always strikes me — how, while having this brilliant model, the model that’s plain dead simple at its heart, the one about DAG of commits, — how every other interface to it manages to ruin it completely?
And it’s not just me — people are complaining about Git complexity on the internet a lot. I’ve seen my fellow developers needing a crash course into even basic Git usage, and many were still puzzled by some “advanced” stuff like rebasing months after starting using it. It’s easy to see how wrong it is: basic Git concepts can be explained in a matter of half an hour on a whiteboard, yet actually touching Git on a computer takes you weeks to get used to. Sure, it feels nice to be accounted for something like a “Git guru”, but, the thing is, I do not know that much about Git’s command-line arguments or advanced tricks. I just see that things are much simpler than they seem to be.

So, what shall we do with it? I suggest we get to the core, remove everything accidental, including any UIs and commands, and keep just fundamental information model. And then we start building from there.
Git model
At the very core, Git is about keeping history of a directory. It can store all of the directory content as a snapshot, and it can store a lot of snapshots effectively. So, as you keep changing your project, you are making these snapshots and Git puts them to its local database. You can later restore any of these snapshots, and it will bring your directory’s content exactly as it was back then. Snapshots are called commits, and we will stick to that term too.
Besides directory’s content and some metadata like author and timestamp, each commit also remembers link to its parent commit. This is important because it helps tracking causality. History in Git is non-linear: there may be several versions of a project co-exisiting in parallel. History forms directed acyclic graph (DAG), a tree of commits with splits (branching) and joins (merges).
Notice that commits and DAG are self-sufficient. They live without branches or remote repositories or stage index or whatever. It’s also important to remember what Git is calling “a branch” has nothing to do with branches in graph terms. Git’s branch is just a pointer to some commit, exactly like a tag is. To avoid confusion, we’ll call them branch pointers.
Grow-only repository
It’s all fun and games, but here comes a chance to make the first serious improvement. You may have noticed that Git warns you a lot. Rebase is dangerous, headless state is dangerous, don’t do push -frebase or commit --amend
Understanding there’s no harm to be done eases things a lot. It encourages experimenting, which is one of the most effective ways to learn new things and to get familiar with them. Imagine this: you start rebase, mess things up, hit Ctrl+Z
Working with working copy
Another step towards safe Git experience is working copy management.
Working copy is just a term for all changes you’ve made to the repo directory and haven’t commited yet, so Git knows nothing about them and is not managing them in any way. One sad case where you may lose your work is when you have “dirty” working copy and want to perfom any other operation with Git. It’s a very common use-case, and what Git recommends is to create temporary work-in-progress commit or stash current changes and return back to them later. Git will, in fact, warn you and refuse to do anything before you get your working copy clean. This is very irritating.
As we’re building our (imaginary) brave new Git interface, let’s make some principles and stick to them. Here’s the first one: never bother user with warnings, and never get in a user’s way. What he wants, he should be able to do. But we cannot lose the user’s data either. So what I propose is to, as soon as you need clean working copy, convert current work in progress into “WIP” commit automatically. It saves the user manual labour of commiting or stashing, and keeps unfinished work safe and accessible. The overall Git experience should feel much smoother and hassle-free.
Switching branches while having dirty working copy (hover to animate)
Keeping 2 dirty working copies (hover to animate)
Unification of working copy and commits brings another major win: it simplifies mental model and brings consistency to working copy interactions. Git is built around commits manipulation, so it’s very logical and consistent to being able to apply all its tools to working copy too. Under the hood, working copy may be treated differently, but for a user there’s no point to be aware of that distinction. From a user’s standpoint, we’ve just removed the concept of working copy altogether, leaving him with the very basic idea — everything is a commit.
This may seem small, but there’re big consequences for Git usage patterns. For example, commiting becomes much more trivial, as you always have WIP commit ready. git commit
Commit by rename (hover to animate)
Stage by split (hover to animate)
By leaving the user with just one concept that everything is a commit, we put him in a very favourable position — all he needs to learn is how to interact with commits. If he knows that, he’ll also be able to manipulate working copy and to stage changes. We simplified things a lot because in traditional Git these operations are done via completely separate set of commands.
Delta algebra
As we more or less know how to commit changes, let’s move to the second most essential thing one can do with Git repo — delta manipulation. Kind of advanced stuff, yet it occurs in everyday Git usage nonetheless. But before discussing that, let me introduce you to commit’s delta-snapshot duality.
As we’ve already learned, commit is a snapshot of repo directory at some point in time. This is technically correct (this is how Git stores commits internally), and this is how commits are used for checkouts. But that’s not the only way one can look at commits. Each commit can also be viewed as delta (or diff, change) of parent’s snapshot and its own. If commit B is based on A, then delta(B) := diff(snapshot(B), snapshot(A)). Deltas are derived, they are not directly stored by Git, but rather calculated on the fly when needed. Also, merge commits cannot be directly expressed as deltas because they are based on more than one commit.
So, we can view a Git repository not only as a series of periodical backups, but also as a series of changes applied on top of one another. Deltas are easier to comprehend and more directly represent “work done” (you usually think in terms of what was changed rather than entire repo state). They also enable a rich set of interactions with repo we’ll call “delta algebra”.
Main operations of delta algebra are: combine deltas (squash), split delta into two, reverse delta. We’ll also need some bridge to/from commits, specifically getting delta from commit and creating commit from delta. Given that, all sort of Git magic can be expressed: rebase, cherry-pick, revert, commit reordering. Important thing to understand is that they all are based on a very basic delta operations — in essence, we always take these changes, combine/
Squash operation (hover to animate)
The main difference from Git is that you expose basic operations instead of high-level shortcuts. Working with fundamental mechanics brings power (there’re more ways to combine basic operations), predictability (as each individual operation is simpler) and eases the learning curve (you’ll be learning the correct mental model from the start).
Using direct manipulation to imitate Git rebase
Using direct manipulation to imitate cherry-pick (hover to animate)
Another important aspect is to make manipulations direct and visual. This always bothers me even in best Git UIs — you see commit tree, you know how you want to rearrange commits, but there’s always that next, very unfortunate step to figure out how to express that in terms of command-line Git commands, which, in its turn, has no direct mappings to your intentions. What proper UI should enable is to select, drag, copy and shuffle commits and branch pointers, including HEAD, directly on the DAG tree. Experience should be much like dragging points in vector graphics editor.
Moving HEAD pointer to imitate Git checkout (hover to animate)
Staying connected
Of course Git is a social tool. While there’s (usually small) point in using it just for yourself, most people use it to collaborate. Git model exposes concept of “remote repositories” and a set of commands to communicate with them: fetch, pull, push and local-remote branches facilities. This is where Git model is a little bit too flexible. But first let’s talk about power of decisions and introduce one more principle.
In some situations, user’s decision is required. Only a human can bring sense and meaning to work, and computer’s job is to provide tools for that. But there’re situations where software asks user about the matters that do not actually require any decision to make. This is dull and tiresome to do operations which add nothing to the job, but are only required for software to continue to run. Sometimes these situations can be easily spotted (like annoying UAC popups), sometimes people are so used to them they think there’s nothing wrong with it (like manual install of bugfix releases), but the criteria is always simple: do I really have a choice? Will my work really, in a qualitative sense, depend on decision I’d make?
So, our next UI principle will be: do not ask user when his decision is not required. Applying this to Git, we should remove any manual branch syncing stuff. Our Git client will always stay online, and will always sync local branches state with remotes. When you create a branch, it gets immediately pushed and visible for all other clients connected to the same repository. If someone else created or advanced any of the branches, it’ll become immediately visible for you. Not a single button click required. Sure, situations when you’ve done changes to the branch and someone else’ve done the same will occur — there’s nothing wrong with that — but these are exceptional cases and in that case two branches will be displayed, local and remote.
There’s a solid foundation for such “always online” experience. git fetch
This is another huge win for us: we’ve removed a whole school of manual syncing commands besides just setting up remote’s URL. No questions to ask, nothing to learn, no place to make a mistake, it just works. And we haven’t really lost anything here because we’ve removed only mechanical operations, ones which do not require user’s decision. From now on, you’ll just commit locally and, magically, everybody else will be able to see your changes. Feels like Dropbox, and this is a big thing. You’ll love that ”always online” experience, I promise.
You may think auto-sync will completely ruin your familiar “commit now, restructure later” workflow. It will not. As you’re working in your branch, you can still reorganise, restructure, reorder and rename commits in your branch. These changes will be incrementally synced to all other peoples’ machines as you go. They’ll initially see your mess, but then they’ll see all the changes you’re doing to make your branch look pretty. All happening without any manual button clicking/
Remember that network connection is not required for our client to work properly. Offline experience is more or less the same, but when you’re connected, you’ll have less buttons to click.
Looks matter
I do believe that the best way to observe and understand such a complex thing as DAG of commits is a visual representation. Command-line just don’t cut it. There’s a bad reputation about lousy Git GUIs in a programmer’s world, and they may have a thing. Current Git clients do limit their users to small subset of basic Git operations and rely on a manual command-line mode for all non-trivial cases. In traditional GUIs, you don’t win that much, therefore there’s little motivation to go for GUI in the first place. We, on the other hand, are talking about full-featured Git client able to cover all use-cases that were previously possible only in a command-line. We also bring direct manipulation and Undo/Redo to the picture which is a significant improvement over what we could ever have in console.
So, it has to be visual, what else? Nothing revolutionary here, just a few tweaks to the current state of affairs:
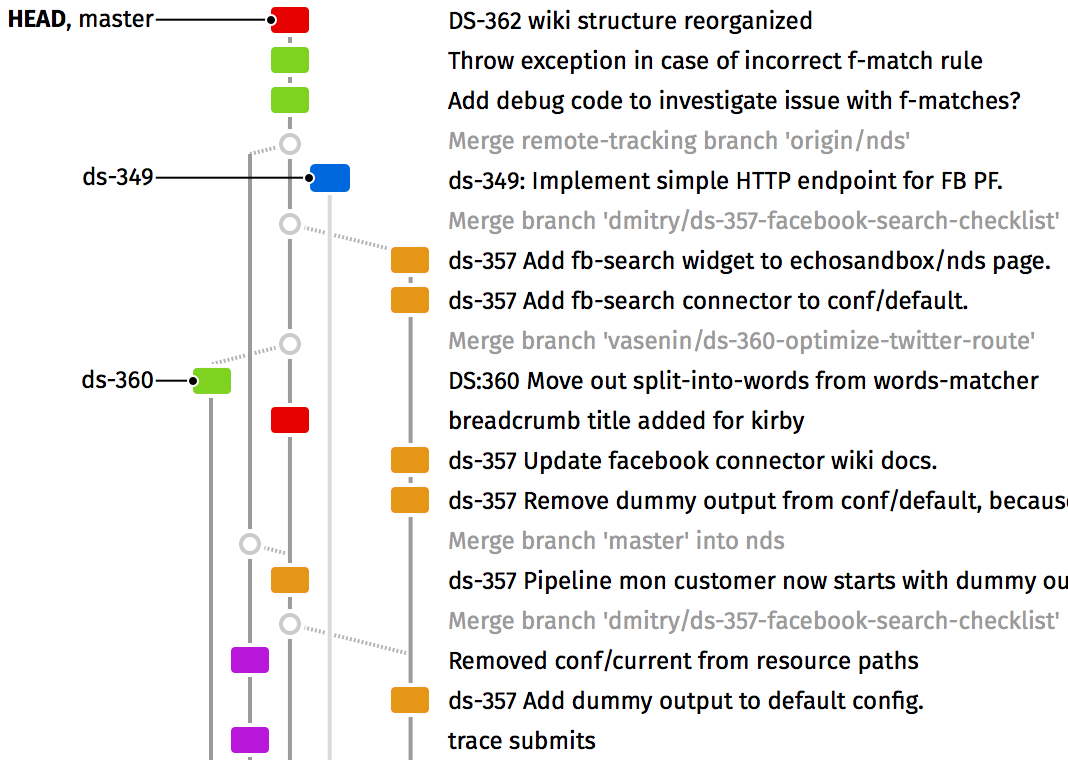
- Branch always occupies vertical column, never bends right or left;
- Commits are colored not by branch color (we keep branches visually separated by previous rule), but by author. Author matters — in a team, you usually either look for a commits by specific teammate (to review or merge), or you’re trying to understand who wrote specific piece;
- Merge commits have a different, much subtler look, because they are not an effort per se, but a place where two other efforts join;
- Parents of the current HEAD highlighted, effectively slightly hiding future and parallel commits;
- Branch labels on the left help scan what you are interested in: branches or commit messages.
Remote interface
There’s one single feature that still makes CLI clients look so appealing: ability to work on another machine. Proxying CLI is ubiquitous, proxying GUI is uncommon and still awkward. Can we possibly answer to that?
Thing is, we actually can. There’s one way to proxy GUI applications that is widely used and, if not as smooth as local apps, at least pretty usable. It’s web. Applications controlled via web browser can be run anywhere you can connect to, yet can have almost all the benefits of native GUI apps.
This is the way all modern apps should be written (if “app as a service” model cannot be used): they start web server and open a browser window, providing all UI though JS and HTML. And I’m not talking about node-webkit nonsense here which combines downsides of a web app (limited system integration) with downsides of a native app (cannot be accessed remotely). No, just a regular web server, honest HTTP port, regular browser window. When used locally, experience is the same as with local app, but we get remote execution, literally, for free. With current state of web technology it won’t be any harder (and may, in fact, sometimes be much easier) to develop apps that way.
This is awkwardly long, let’s sum it up
We gave a set of recommendations on how Git UI can be improved not on a cosmetic, but on a very fundamental level. Our concept makes Git more usable, powerful and easier to learn mainly by unifying redundant concepts and adding some new features. Here they are:
- Remove warnings as Git repo is immutable and cannot lose data
- Provide undo/redo
- Everything is a commit. Treat working copy and staging area as commits, allow regular commit operations to be applied to them
- Provide basic delta manipulations interface
- Direct interaction with visual DAG tree
- Provide always online experience, automatically sync branches with remotes
- Improve looks of DAG tree by providing better coloring and layout
- Make it web app in order to make it accessible from remote machines via browser
In spite of the fact that all this sounds revolutinary, it’s important that we can keep full compatibility with regular Git repositories and allow different Git clients to be used together.
I also ask not to discard all this nonsense right away, but at least give it a fair round of thought. My recommendations, if applied in their entirety, can radically change Git experience. They can move Git from advanced, hacky league to the mainstream and enable adoption of VCS by very wide groups of people. While this is still a concept and obviosly requires a hell of a job to become reality, my hope is that somebody working on a Git interface can borrow from these ideas and we all will get better Git client someday.
