Humble Chronicles: Managing State with Signals
After the previous post, I figured that the best way to decide on the direction for Humble UI is to make an experiment.
And I did. I implemented a reactive/incremental computation engine (signals) and wrote a simple TodoMVC in it. Following are my thoughts on it.
Signals
The idea behind signals is very simple: you declare some mutable (!) data sources:
(s/defsignal *width
16)
(s/defsignal *height
9)And then create a derived (computed) state that depends on those:
(s/defsignal *area
(println "Computing area of" @*width "x" @*height)
(* @*width @*height))Now, the first time you dereference *area, it is computed:
@*area => 144
;; Computing area of 16 x 9After that, any subsequent read is cached (notice the lack of stdout):
@*area => 144If any of the sources change, it is marked as dirty (but not immediately recomputed):
(s/reset! *width 20)But if you try to read *area again, it will recompute and cache its value again:
@*area => 180
;; Computing area of 20 x 9
@*area => 180
;; (no println)You can check out implementation here and some usage examples here. The implementation is a proof-of-concept, so maybe don’t use it in production.
Stable object references
The appeal of signals is that, when data changes, only the necessary minimum of computations happens. This is, of course, cool, but not entirely free — it comes at a cost of some overhead for managing the dependencies.
I was particularly interested in using signals for Humble UI because they provide stable references. Let’s say you have a tabbed interface that has a checkbox that enables a text field:
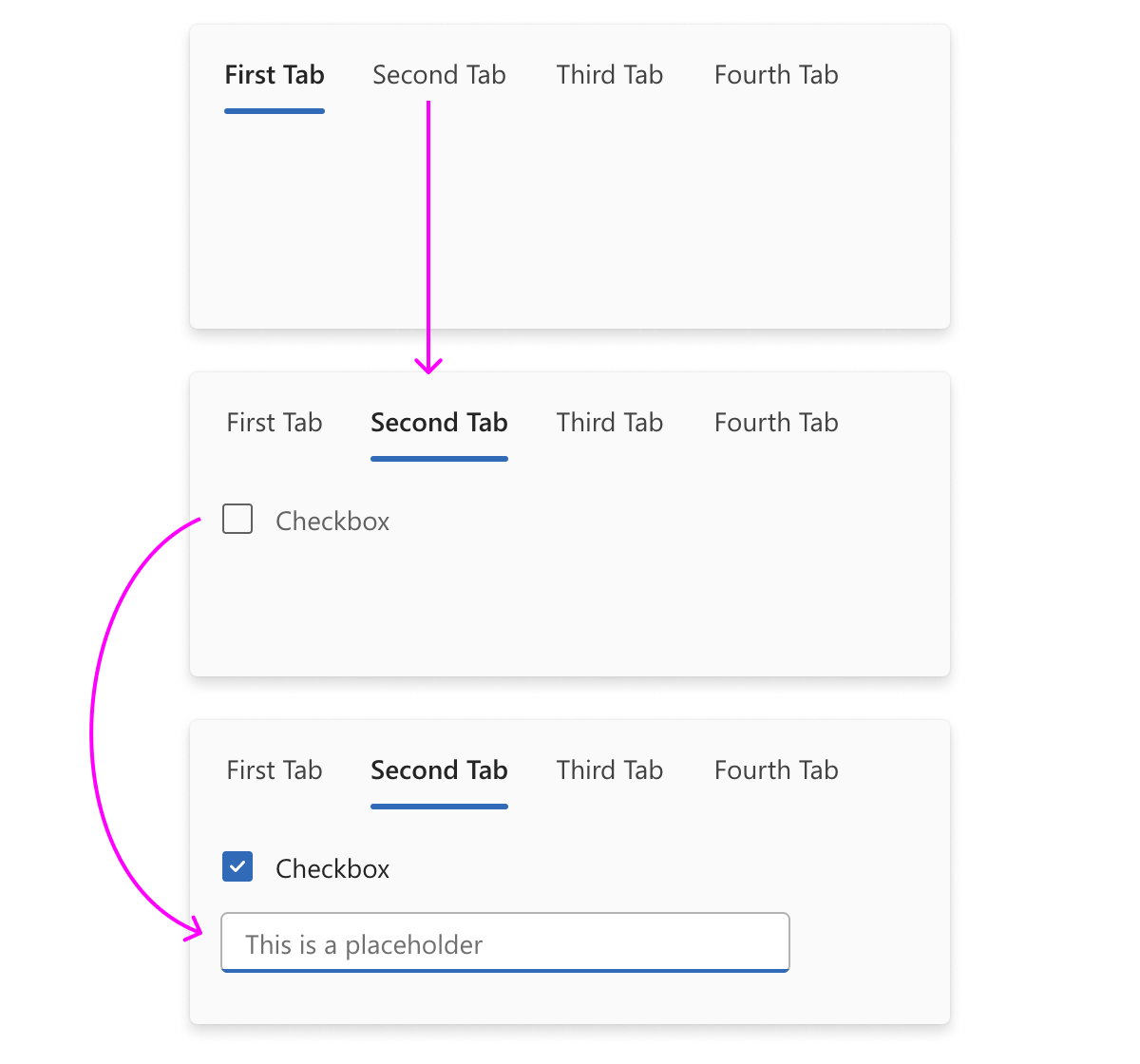
Now, our state might look somewhat like this:
(s/defsignal *tab
:first)
(s/defsignal *checked?
false)
(s/defsignal *text
nil)
(s/defsignal *tab-content
(column
(ui/checkbox *checked?)
(when @*checked?
(ui/text-field *text))))
(s/defsignal *app
(case @*tab
:first ...
:second *tab-content
:third ...))and the beauty of it is unless the user switches a tab or plays with a checkbox, *tab-content will be cached and NOT recomputed because its dependencies do not change!
And that means that no matter how many times we dereference *tab-content e.g. for rendering or layout, it will always return exactly the same instance of the checkbox and text field. As in, the same object. Same DOM node, if we were in the browser.
Cool? Cool! No diffing needed. No state tracking and positional memoization either. We can put all internal state into objects as fields and not invent any special “more persistent” storage solution at all!
This was my main motivation to look into incremental computations. I don’t really care about optimal performance, because—how much is there to compute in UI anyways?
And also—it’s not obvious to me that if you make every + and concat incremental it’ll be a net win because of overhead. But stable objects in a dynamic enough UI? Lack of diffing and VDOM? This is something I can use.
Props drilling
One of the examples where VDOM model doesn’t shine is props drilling. Imagine an app like this:
(ui/default-theme
{:font-ui ...}
(ui/column
(ui/row
(ui/tabs
...
(ui/tab
(ui/button
(ui/label "Hello")))))))The actual details don’t matter, but the point is: there’s a default theme at the very top of your app and a label somewhere deep down.
If you pass font-ui as an argument to every component, it will create a false dependency for every intermediate container that it passes through. When the time for the update comes, the whole UI will be re-created:
In a perfect world, though, font-ui change should only affect components that actually use that font. E.g. it shouldn’t affect paddings, backgrounds, or scrolls, but should affect labels and paragraphs.
Well, incremental computation solves this problem beautifully! If you make your default font a signal, then only components that actually read it will subscribe to its changes:
On the other hand, how often do you change fonts in the entire app? Should it really be optimized? The question of whether this use case is important remains open.
Reactive vs Incremental
Now let’s dig into implementation details a little bit. What we have so far is, I believe, called reactive, but not incremental. To be called incremental we must somehow reuse, not just re-run, previous computations.
A simple example. Imagine we have a list of todos and a function to render them. Then we can define our UI like this:
(s/defsignal *todos
...)
(s/defsignal *column
(ui/column
(map render-todo @*todos)))This would work fine the first time, but if we add a new to-do, the whole list will be re-rendered. *todos changes, *column body gets re-executed, render-todo is applied to every todo again by map.
To solve just this problem, we could introduce incremental s/map that only re-computes the mappings that were not computed before:
(def column
(ui/column
(s/map render-todo *todos)))Under the hood, s/map caches previous computation and its result and, when re-evaluated, tries to reuse it as much as possible. Meaning, if it already saw the same todo before, it will return a cached version of (render-todo todo) instead of calculating it anew.
Two important things to note here. First, if we care about object identities, we have to use incremental map. Otherwise adding new todo to the end of the list will reset the internal component state of every other one. Not good!
Second, although “incremental map” sounds fancy and smart, under the hood it does the same thing that React does: diffing. It diffs new collection against previous collection and tries to find matches.
It is (probably) a perf win overall, but, more importantly, diff still does happen. That’s the reason why all incremental frameworks have their own versions of for/map:
{#each arr as el}
<li>{el}</li>
{/each}I can imagine it could be better when a diff happens on the data layer instead of on the final UI layer because generated UI is usually much larger than the source data. Either way, at least you can choose where it happens.
The bad news is, you have to think about it, whereas in React model you usually don’t bother with such minute details at all.
One can imagine that we’ll need incremental versions of filter, concat, reduce etc, and our users will have to learn about them and use them if they want to keep stable identities. And we’ll have to provide enough incremental versions of base core functions to keep everyone happy, and potentially teach them to write their own. Sounds harsh.
Effects
One important feature we’re missing in our incremental framework is effects.
We implement a mixed push/pull model: recalculating values is lazy (not done until explicitly requested), but marking as dirty is eager (immediate dependencies are marked as :dirty and their transitive deps are marked with :check, which means might or might not be dirty):
(s/defsignal *a
1)
(s/defsignal *b
(+ 10 @*a))
(s/defsignal *c
(+ 100 @*b))
@*a ; => 1
@*b ; => 11
@*c ; => 111
(:state *b) ; => :clean
(:value *b) ; => 11
(s/reset! *a 2)
(:state *b) ; => :dirty
(:value *b) ; => 11
(:state *c) ; => :check
(:value *c) ; => 111
@*b ; => 12
(:state *c) ; => :dirty
(:value *c) ; => 111
@*c ; => 112Or for us visual thinkers:
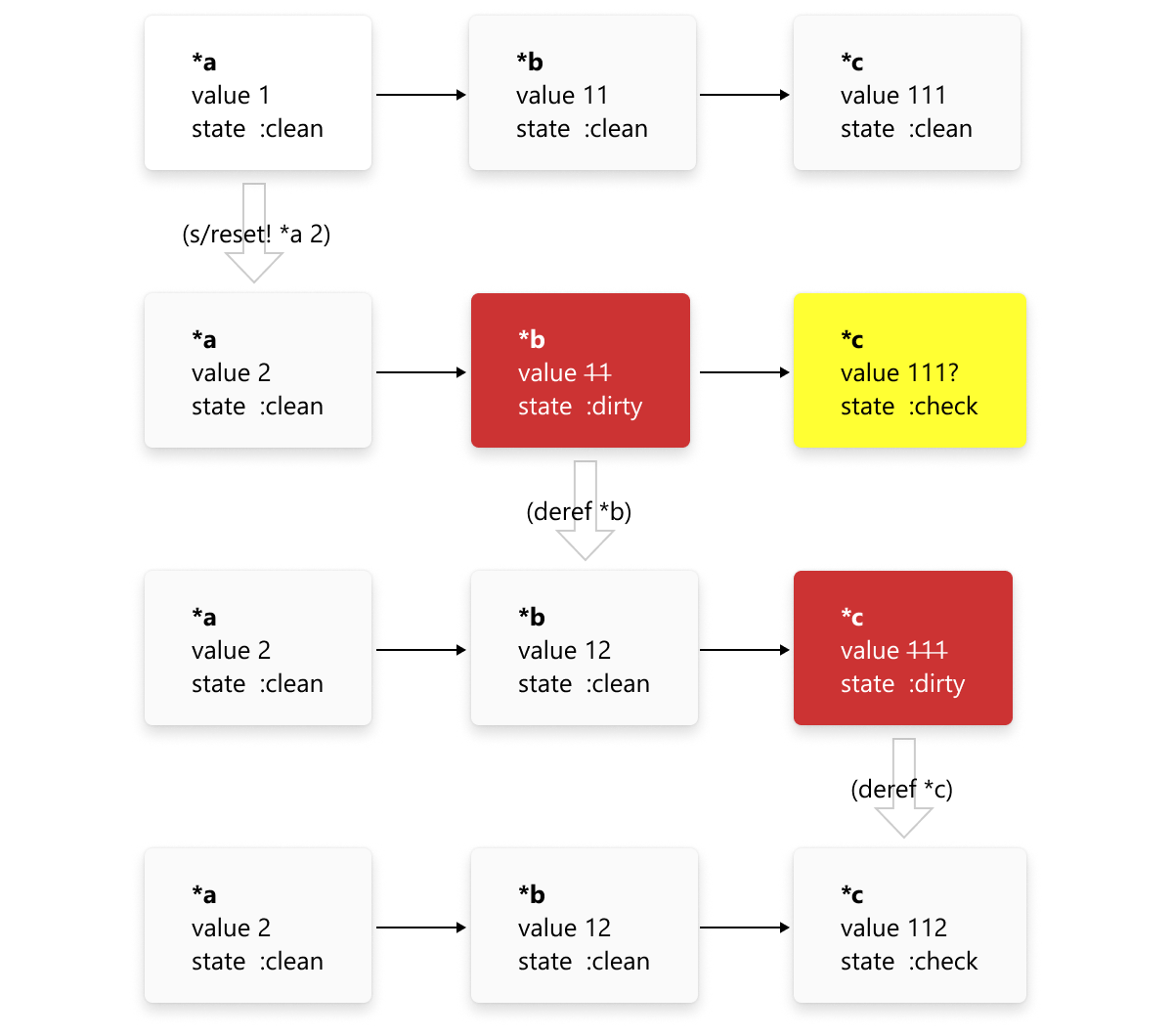
For details, see Reactively algorithm description.
An effect is a signal that watches when it gets marked :check (something down the deps tree has changed) and forces its dependencies to see if any of them are actually :dirty. If any of them are, it evaluates its body:
(s/defsignal *a
1)
(s/defsignal *b
(mod @*a 3))
(s/effect [*b]
(println @*a "mod 3 =" @*b))
(s/reset! *a 2) ; => "2 mod 3 = 2"
(s/reset! *a 3) ; => "3 mod 3 = 0"
(s/reset! *a 6) ; => (no stdout: *b didn’t change)This is exactly what we need to schedule re-renders. We put an effect as a downstream dependency on every signal that was read during the last draw. That means we’ll create an explicit dependency for everything that affected the final picture one way or another.
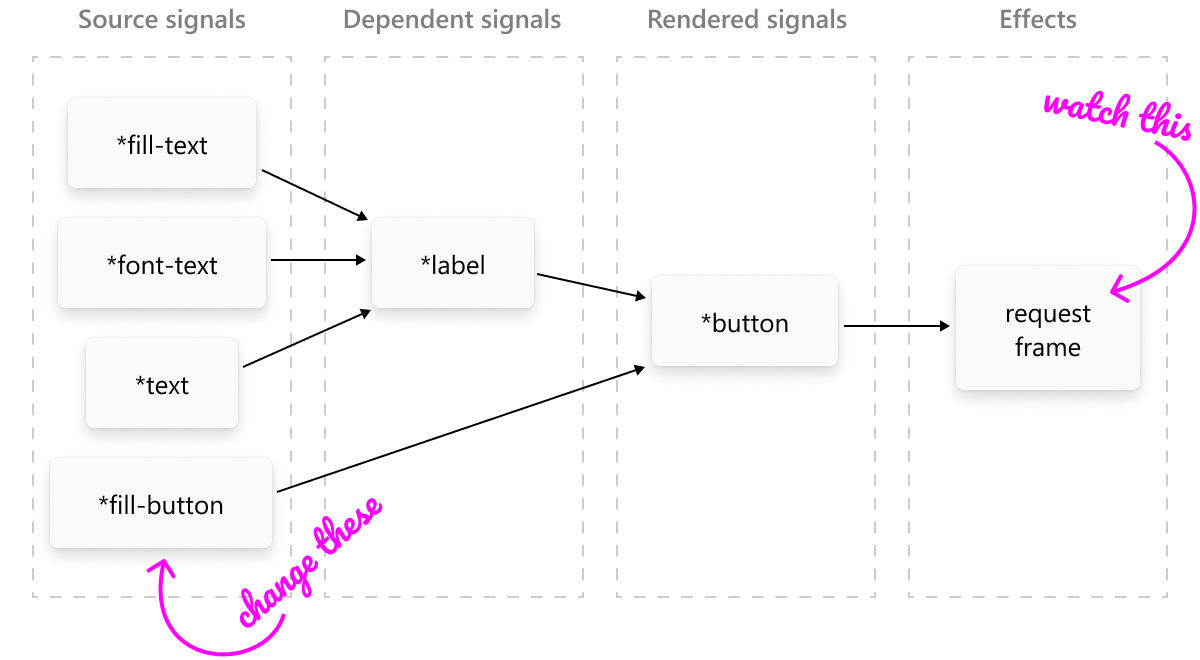
Then, when any of the sources change and the redraw effect is actually a downstream dependency on it, we’ll trigger a new redraw.
Disposing signals
What I did have problems with is resource management. First, let’s consider something like this:
(s/defsignal *object
"world")
(def label
(s/signal (str "Hello, " @*object "!")))Now imagine we lose a reference to the label. Irresponsible, I know, but things happen, especially in end-user code. The simplest example: we’re in REPL and we re-evaluate (def label ...) again. What will happen?
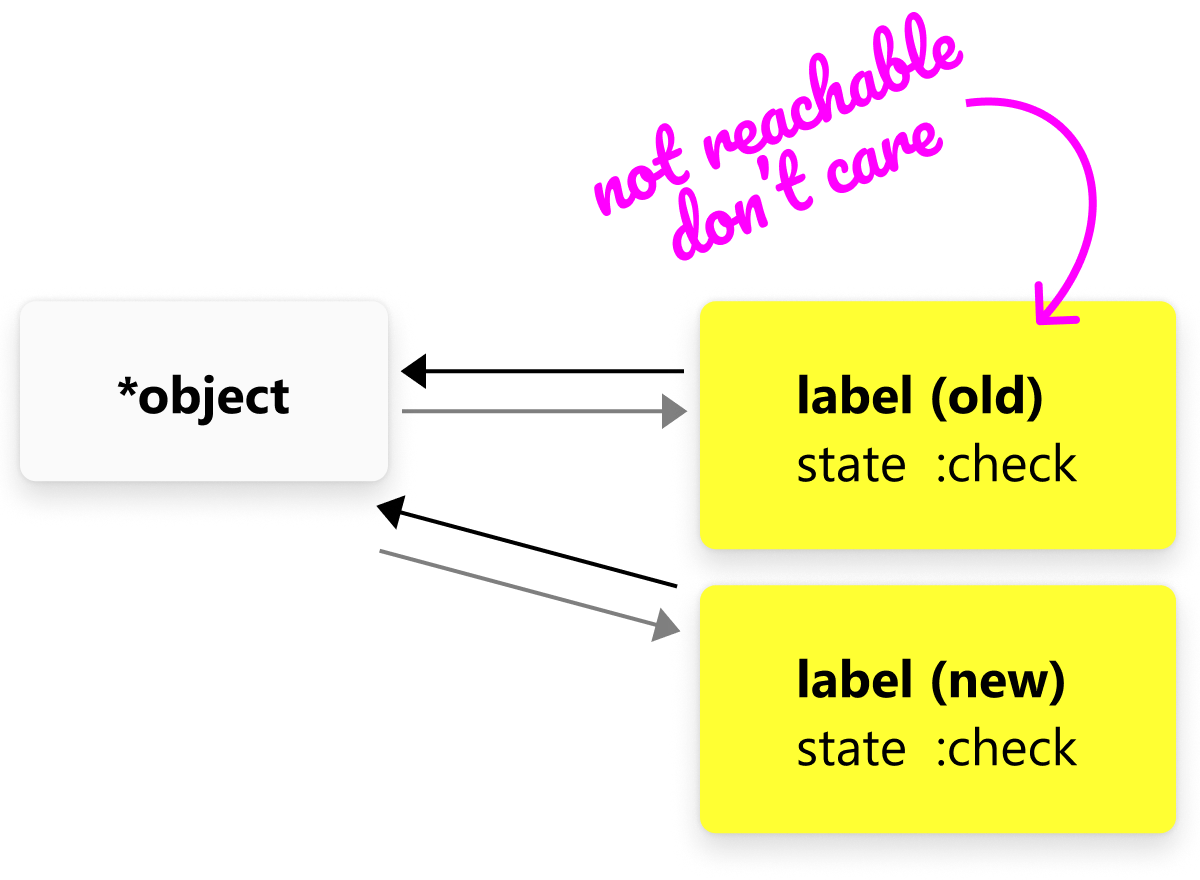
Well, due to the nature of signals, they actually keep references to both upstream (for re-calculation) and downstream (for invalidation) dependencies. Meaning, the previous version of the signal will still be referenced from *object along with the new one:

We can introduce dispose method that could be called to unregister itself from upstream, but nobody can guarantee that users will call that in time. It’s so easy to accidentally lose a reference in a garbage-collected language!
And this is what I am struggling with. The signal network has to be dynamic. Meaning, new dependencies will come and go. But de-registering something doesn’t really feel natural in Clojure or even Java code, and there’s no way to enforce that every resource that is no longer needed will be properly disposed of.
A common solution is to make downstream references weak. That means, if we lost all references to the dependant signal (label on the picture below), it will eventually be garbage collected.

What I don’t like about that solution (that we use anyways in the prototype) is that until GC is called, those unnecessary dependencies still hang around and take resources e.g. during downstream invalidation.
One idea is to dispose of signals explicitly when their component unmounts. It works for some signals, but not in general. Consider this:
(s/defsignal *text
"Hello")
(ui/label *text)*text signal is created outside of the label and shouldn’t be disposed of by it. At the same time,
(ui/label
(s/signal (str @*text ", world!")))In this case, the signal is created specifically for the label, thus should be disposed of at the same time as the label. But how to express that?
Keep in mind that we probably want both use cases at the same time:
(ui/column
(ui/header *text)
(ui/label
(s/signal (str @*text ", world!")))
(ui/label *text))Eventually, unused signals will be cleaned up by GC, so we can rely on that. I’m just not sure what sorts of problems it might cause in practice.
Disposing components
Same problem I have with signals I also have with components. Because all components are values, nothing stops me from saving them in a var, using them multiple times, etc. Consider this UI:
(s/defsignal *cond
true)
(def the-label
(ui/label "Hello"))
(def *ui
(s/signal
(if @*cond
the-label
(ui/label "Not hello"))))If we toggle *cond on and off, the-label will appear and disappear from our UI, calling on-mount and on-unmount multiple times. So if we do some resource cleanup in on-unmount, we should somehow restore it in on-mount? Feels strange, but why not?
(core/deftype+ Label [*paint *text ^:mut *line]
protocols/ILifecycle
(-on-mount-impl [_]
(set! *line
(s/signal
(.shapeLine
core/shaper
(str (s/maybe-read *text))
@*font-ui
ShapingOptions/DEFAULT))))
(-on-unmount-impl [_]
(s/dispose! *line)
(set! *line nil)))This way, if a component needs some heavy resources for rendering (textures, pre-rendered lines, or other native resources) it can clean it up and restore only when it’s actually on the screen. Or rely on GC once again (not recommended).
Mounting components
Another thing that I used to take for granted since the world switched to React: lifecycle callbacks. A lot of stuff comes down to these callbacks. Enabling/disabling signals. Freeing expensive resources held by components. Users’ use cases, like setting a timer or making a fetch request. It is so convenient to be able to tie some expensive resource’s lifetime to the lifetime of a component. We certainly want these!
How does React do it? Well, it takes mount/unmount API away from you and takes control over it, so it can guarantee to call you back at the right time.
The solution I came up with is very simple: the component is mounted if it was drawn during render, and not mounted otherwise. At the very top level, I’m keeping track of everything that was rendered last frame and what is rendered this frame. For new stuff, -on-mount is called, for stuff that’s no longer visible, -on-unmount. The gotcha here is, as I said above, that some components might “come back” after being unmounted. I guess it’s ok?
Gotchas
Working with an incremental framework breaks both imperative and functional intuition. It’s a whole other thing. I made a lot of mistakes and had to think about stuff I usually don’t have to think about. Here are a few gotchas:
Dependency too wide
Imagine we want to render a TODO from very simple EDN data:

We might write something like this:
(defn render-todo [*todo]
(let [*text (s/signal
(str (:id @*todo)))]
(ui/label *text)))This render function returns a label object that has a signal as its text. So far so good.
The problem is, we over-depend here: we only use :id from *todo but we depend on the entire thing. A better solution would be:
(defn render-todo [*todo]
(let [*id (s/signal (:id @*todo))
*text (s/signal (str *id))]
(ui/label *text)))which seems a bit too tedious to write. It probably doesn’t matter all that much in this particular case, but what if computations are more expensive?
My point is: it’s too easy to make this mistake.
Ambrose Bonnaire-Sergeant has pointed out that Reagent and CljFX solve this by providing an explicit API:
@(subscribe [:items])Dependency at the wrong time
Imagine you have a UI like this:
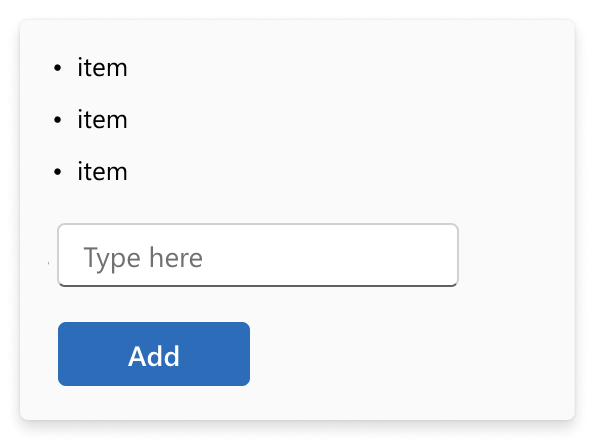
You have a signal that is hooked up to your text field and a button that converts it into a label:
(s/defsignal *text
"Your name")
(s/defsignal *list
[])
(def app
(ui/column
(s/mapv ui/label *list)
(ui/text-field {:placeholder "Type here"}
*text)
(ui/button
#(s/swap! *list conj *text)
(ui/label "Add"))))Do you see it? We actually store the original signal in *list instead of making a copy. This way, when we edit text, every element in our list will also be edited!
We might fix it like so:
#(s/swap! *list conj (s/signal @*text))but it’s no good either.
Yes, we create a new signal, but it depends on the old one :) This is an API problem, and I think maybe I should have separate functions for source signals and derived signals. Right now the proper way to write it would be:
#(let [text @*text]
(s/swap! *list conj (s/signal text)))which is almost identical! but the result is very different.
It reminds me a lot about Clojure laziness puzzles, which is both ok (we all learned to deal with them) and not so much (the best way to deal with laziness is not to use it).
Recomputing too much
There’s another gotcha in the previous example. column takes a collection or a signal that contains a collection, so we have to satisfy that:
(ui/column
(s/signal
(concat
(mapv ui/label @*list)
[(ui/text-field ...)
(ui/button ...)]))))But now our s/signal will re-create a text-field and a button each time *list changes. The solution might be:
(let [text-field (ui/text-field ...)
button (ui/button ...)]
(ui/column
(s/signal
(concat
(mapv ui/label @*list)
[text-field
button]))))which, again, kind of breaks referential transparency. Depending on where we allocate our components, an app behaves differently. Doesn’t matter for the button, as it doesn’t have an internal state, but does matter for the text field.
Alternatively, we might introduce a version of concat that accepts both signals wrapping sequences as well as sequence values. Then argument evaluation will lock the text-field value for us:
(ui/column
(s/signal
(s/concat
(s/mapv ui/label *list)
[(ui/text-field ...)
(ui/button ...)])))Ambiguity
It was not always clear to me which parts of the state should be signals and which should be values. Right now, for example, a list of todos is signal containing signals that point to todos:
(defn random-todo []
{:id (rand-int 1000)
:checked? (rand-nth [true false])})
(s/defsignal *todos
[(s/signal (random-todo))
(s/signal (random-todo))
(s/signal (random-todo))
...])This way list of todos could be decoupled from the todos themselves. When we add new todo, we need to change the list and generate a new component. But when an individual todo is e.g. toggled, it’s handled entirely inside and shouldn’t affect the list.
I guess this solution is okay, although double-nested mutable structures do give me pause.
Could the same be done “single atom”-style? Probably, with some sort of keyed map operator and lenses?
(s/defsignal *todos
[(random-todo)
(random-todo)
(random-todo)
...])
(def *todo-0
(s/signal
{:read (nth @*todos 0)
:write #(s/update *todos assoc 0 %)}))The same ambiguity problem happens here:
(s/defsignal *text
"Hello")
(ui/label *text)or
(s/signal
(ui/label @*text))Should I use a label that contains a signal or a signal that contains a label? Both are viable.
This is not necessarily a problem, just an observation. I guess I prefer Python’s “There should be one—and preferably only one—obvious way to do it” to Perl’s “There’s more than one way to do it”.
Repeating computations
I have a few constants defined in my app, including *scale (UI scale, e.g. 2.0 on Retina) and *padding (in logical pixels, e.g. 10).
But actual rendering requires screen pixels, not UI pixels. For that, I was using the derived signal calculated inside the padding constructor:
(defn padding [*amount]
(map->Padding
{:amount (s/signal (* @*scale @*amount))}))The problem? I was using default *padding everywhere:
(padding *padding ...)
...
(padding *padding ...)
...
(padding *padding ...)
...This way I ended up with dozens of equivalent signals (different identities, same value, dependencies, and function) that multiply the same numbers to get the same result.
Is it bad? In this case, probably not. It just doesn’t feel as clean, considering that the rest of the app uses the absolute required minimum of computations and the dependency graph is carefully constructed.
But I don’t see a way to merge identical signals together, either. I guess we’ll have to live with this imperfection.
Pre-compilation
I started this experiment inspired by Svelte, Solid, and Electric Clojure. All of them have compilation steps that I wanted to avoid.
The most non-obvious result I get from this is that it looks like you need pre-compilation for better ergonomics and resource management. Both of these problems go away if we don’t let users interact with our incremental engine directly, but instead, do it for them.
We can replace calls to if/map/concat with their incremental versions transparently, track dependencies reliably, and add dispose calls where needed—basically, all these things you can’t trust humans to get right.
I am also getting reports that Reagent (that has a similar thing, r/track) is hard to use correctly at scale. Can anyone confirm?
Maybe it’s worth running another experiment to see if I can get pre-compilation working and how much it helps.
Results
Some preliminary results from the experiment:
It works
After some massaging, I was able to build incremental TodoMVC that keeps the state of its components that do not directly change.
Here’s a video:
The magenta outline means that the component was just created and is rendered for the first time.
Notice how when I add new TODO only its row is highlighted. That’s because the rest reuses the same components that were created before.
When you switch between tabs, it causes some of the rows to be filtered out. When you go back to “All”, only the ones that were not visible are recreated.
Also, notice the same effect on tabs: when you switch e.g. from “All” to “Active”, “All” becomes a button but “Active” becomes just a label, so they both have to be recreated. But “Completed” stays a button, so it doesn’t get recreated.
And the last thing: when I toggle TODOs, nothing gets highlighted. This is because I made labels accept signals as text:
(s/defsignal *text
"Hello")
(ui/label *text)So the label could stay the same while the text it displays changes. Not necessary, but feels neat, actually. Another way to do it would’ve been:
(s/signal
(ui/label @*text))Then it would be highlighted on the toggle:
It feels very satisfying
...knowing no computation is wasted on diffs and only the necessary minimum of UI is recreated.
Props drilling works
I made UI scale, padding, and button fill color signals and when I change them necessary parts of UI are updated:
This feels very satisfying, too: knowing that you made the dependency very explicit and very precise, not the hacky “let’s just reset everything just in case” way. And it requires no special setup, it “just works”.
No VDOM needed
I don’t have to implement VDOM and diffing! And I don’t need both heavy- and lightweight versions of each component. I don’t need to track the state separately from the components. That’s a huge burden off my shoulders.
We need incremental algorithms
I do need to provide a set of incremental algorithms. Incremental map, incremental filter, concat etc. for macro, too.
Ideally, we want users to be able to write their own.
It breaks intuition
Working with incremental computations could be tricky. Making a mistake is easy, and double-checking yourself is hard, so it’s hard to know if you are doing the right thing.
But it seems that the stakes are not that high: the worst that could happen is you re-create too much and your performance suffers. I’d say it’s a ~similar deal you get with React.
Is there a deeper reason?
There’s probably a good reason React won and FRP/incremental remain marginal technologies that have been tried dozens of times. I understand the appeal, but I also see how it’s not everybody’s cup of tea.
OTOH, Reagent seems to be doing fine in Clojure land, although many people prefer to pair it with re-frame.
Source code
If you are curious, the code is on Github. The run script is at scripts/incremental.sh.
Let me know what you think! And I’m going to try VDOM approach next. And then I guess I’ll have to make a decision matrix.
