Local, first, forever
So I was at the Local-First Conf the other day, listening to Martin Kleppmann, and this slide caught my attention:
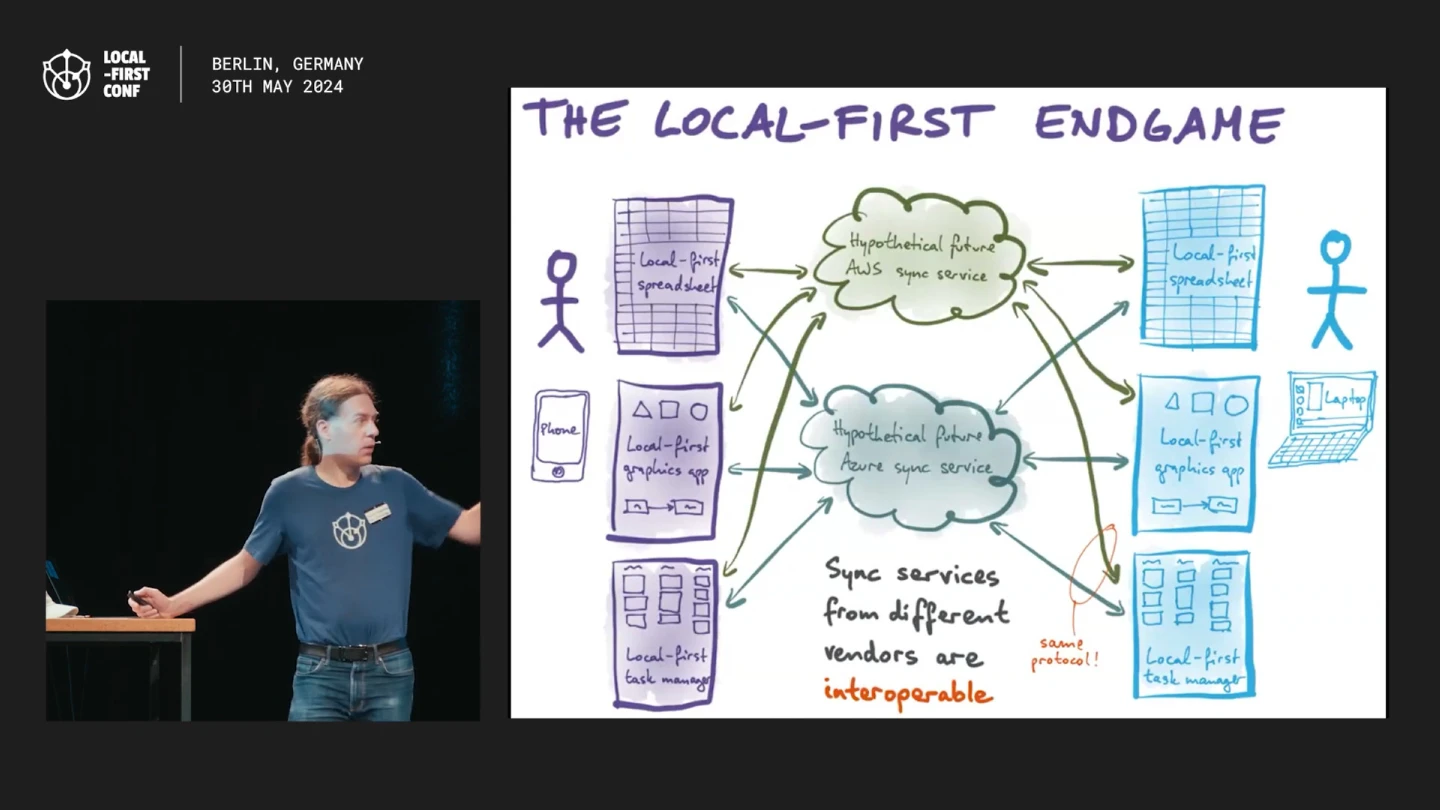
Specifically, this part:

But first, some context.
What is local-first?
For the long version, go to Ink & Switch, who coined the term. Or listen for Peter van Hardenberg explaining it on LocalFirst.fm.
Here’s my short version:
- It’s software.
- That prefers keeping your data local.
- But it still goes to the internet occasionally to sync with other users, fetch data, back up, etc.
If it doesn’t go to the internet at all, it’s just local software.
If it doesn’t work offline with data it already has, then it’s just normal cloud software. You all know the type — sorry, Dave, I can’t play the song I just downloaded because your internet disappeared for one second...
But somewhere in the middle — local-first. We love it because it’s good for the end user, you and me, not for the corporations that produce it.
What’s the problem with local-first?
The goal of local-first software is to get control back into the hands of the user, right? You own the data (literally, it’s on your device), yada-yada-yada. That part works great.
However, local-first software still has this online component. For example, personal local-first software still needs to sync between your own devices. And syncing doesn’t work without a server...
So here we have a problem: somebody writes local-first software. Everybody who bought it can use it until the heat death of the universe. They own it.
But if the company goes out of business, syncing will stop working. And companies go out of business all the time.
What do we do?
Cue Dropbox
The solution is to use something widely available that will probably outlive our company. We need something popular, accessible to everyone, has multiple implementations, and can serve as a sync server.
And what’s the most common end-user application of cloud sync?
Dropbox! Well, not necessarily Dropbox, but any cloud-based file-syncing solution. iCloud Drive, OneDrive, Google Drive, Syncthing, etc.
It’s perfect — many people already have it. There are multiple implementations, so if Microsoft or Apple go out of business, people can always switch to alternatives. File syncing is a commodity.
But file syncing is a “dumb” protocol. You can’t “hook” into sync events, or update notifications, or conflict resolution. There isn’t much API; you just save files and they get synced. In case of conflict, best case, you get two files. Worst — you get only one :)
This simplicity has an upside and a downside. The upside is: if you can work with that, it would work everywhere. That’s the interoperability part from Martin’s talk.
The downside is: you can’t do much with it, and it probably won’t be optimal. But will it be enough?
Version 1: Super-naive
Let’s just save our state in a file and let Dropbox sync it (in my case, I’m using Syncthing, but it’s the same idea. From now on, I’ll use “Dropbox” as a common noun).
Simple:
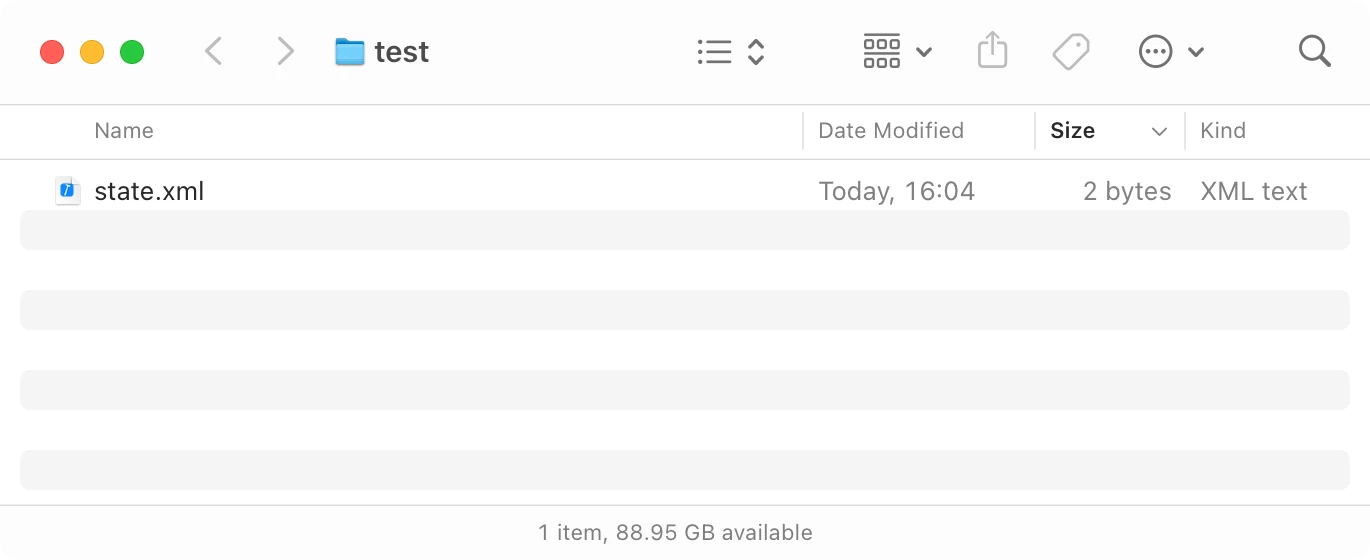
But what happens if you change the state on two machines? Well, you get a conflict file:
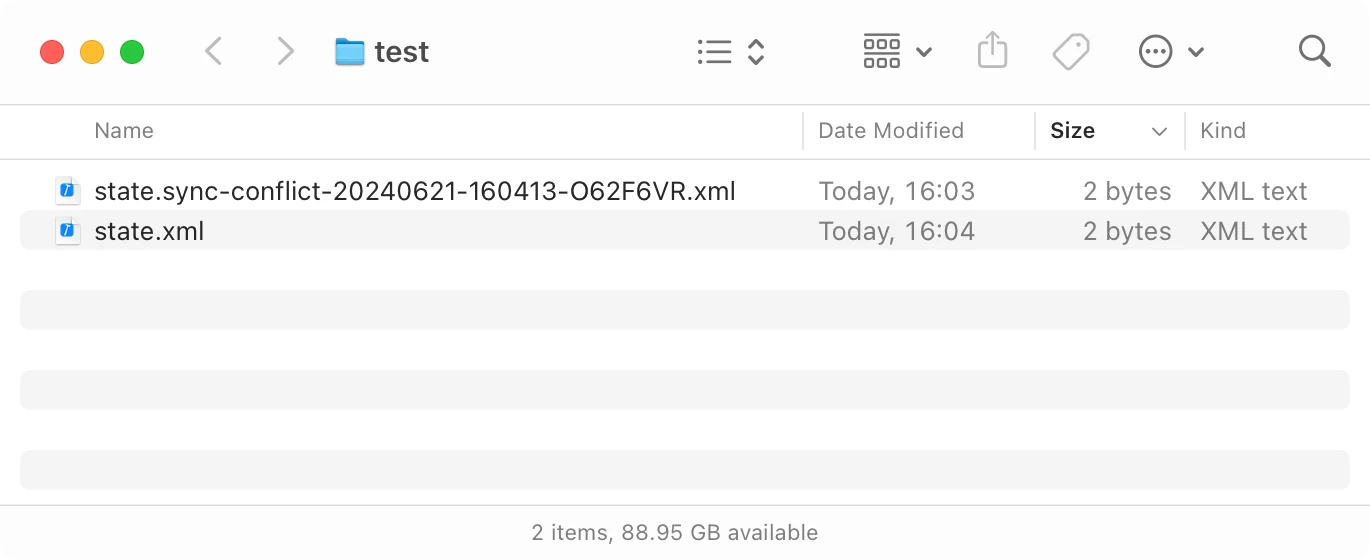
Normally, it would’ve been a problem. But it’s not if you are using CRDT!
CRDT is a collection of data types that all share a very nice property: they can always be merged. It’s not always the perfect merge, and not everything can be made into a CRDT, but IF you can put your data into a CRDT, you can be sure: all merges will go without conflicts.
With CRDT, we can solve conflicts by opening both files, merging states, and saving back to state.xml. Simple!
Even in this form, Dropbox as a common sync layer works! There are some downsides, though:
- conflicting file names are different between providers,
- some providers might not handle conflicts at all,
- it needs state-based CRDT.
Version 2: A file per client
The only way to avoid conflicts is to always edit locally. So let’s give each client its own file!
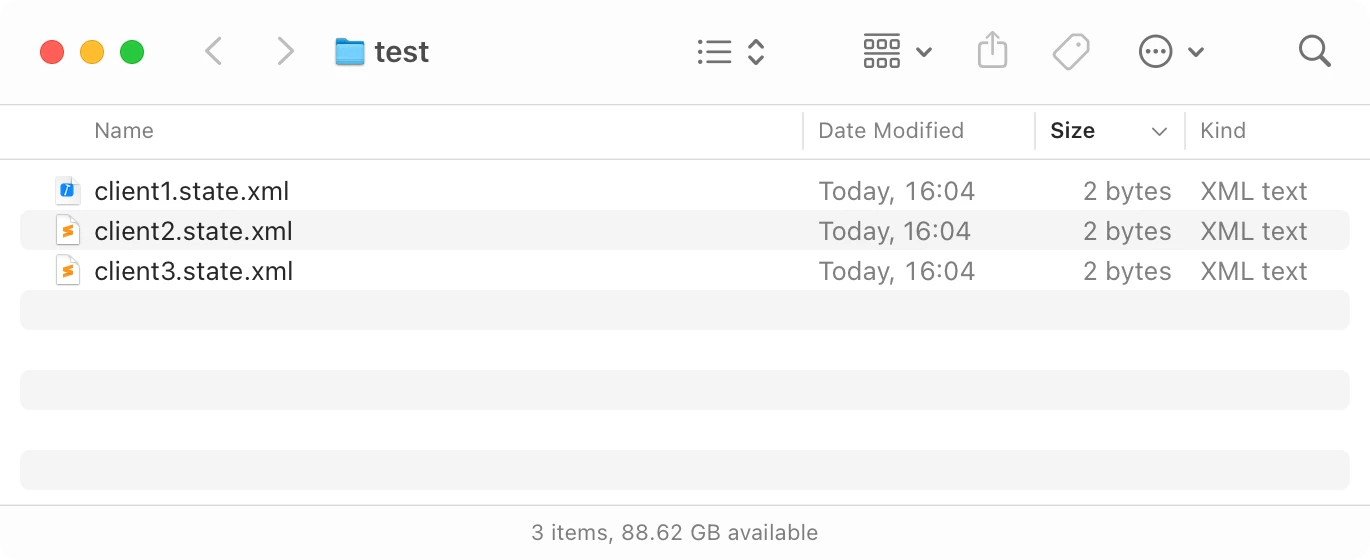
Now we just watch when files from other clients get changed and merge them with our own.
And because each file is only edited on one machine, Dropbox will not report any conflicts. Any conflicts inside the data will be resolved by us via CRDT magic.
Version 3: Operations-based
What if your CRDT is operation-based? Meaning, it’s easier to send operations around, not the whole state?
You can always write operations into a separate append-only file. Again, each client only writes to its own, so no conflicts on the Dropbox level:
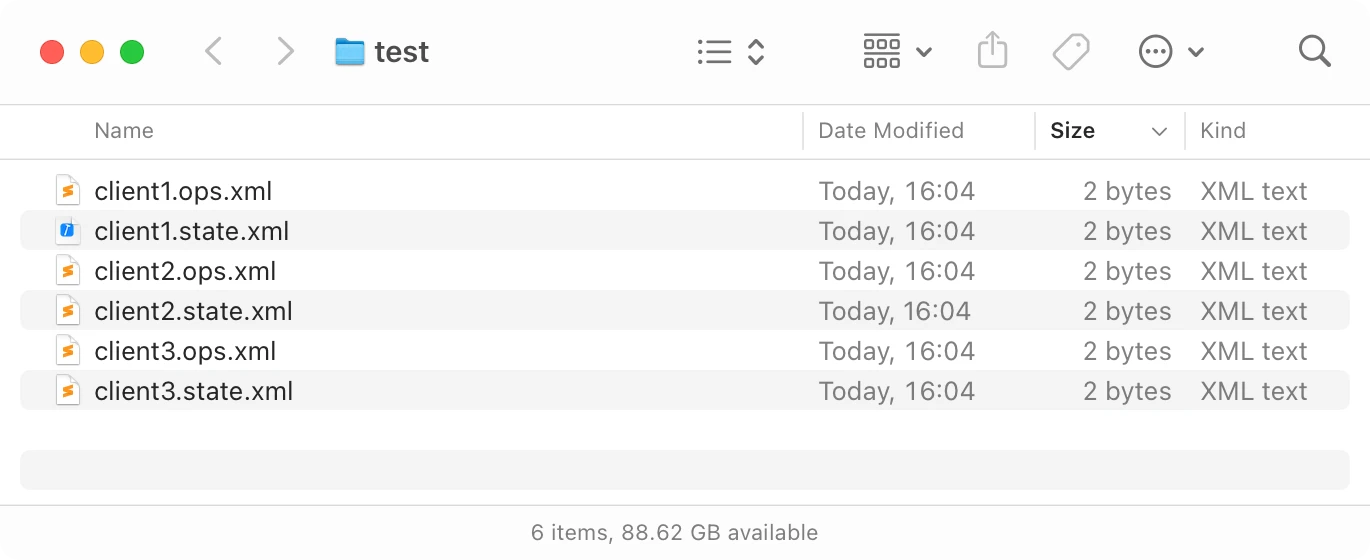
Now, the operations log can grow quite long, and we can’t count on Dropbox to reliably and efficiently sync only parts of the file that were updated.
In that case, we split operations into chunks. Less work for Dropbox to sync and less for us to catch up:
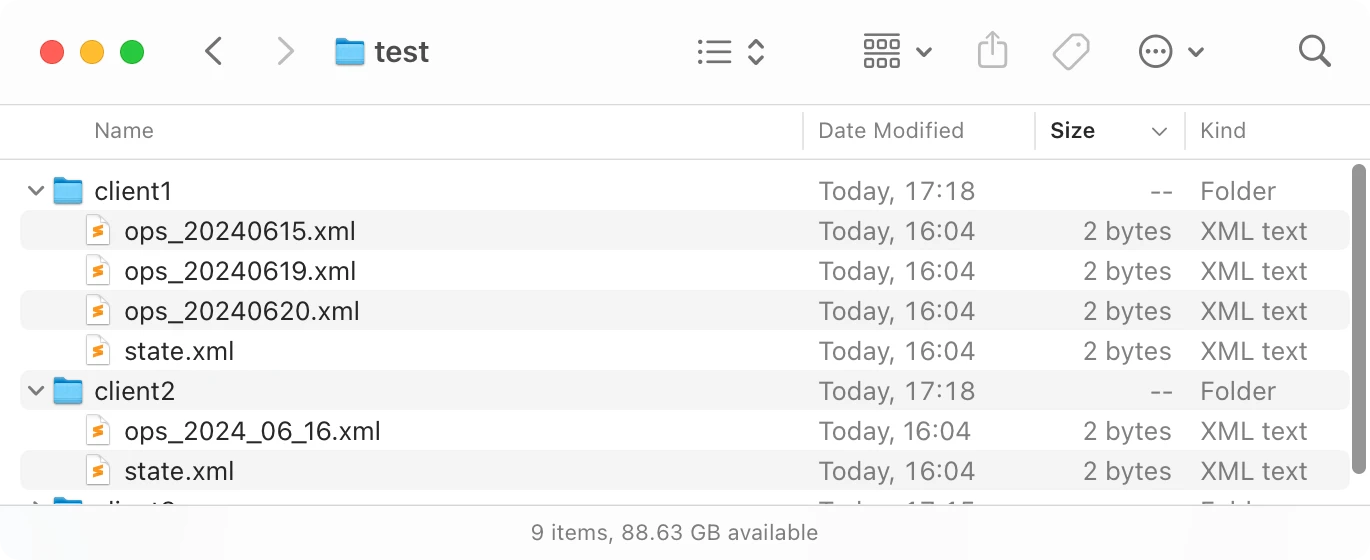
You can, of course, save the position in the file to only apply operations you haven’t seen. Basic stuff.
Theoretically, you should be able to do operational transformations this way, too.
Demo
A very simple proof-of-concept demo is at github.com/tonsky/crdt-filesync.
Here’s a video of it in action:
Under the hood, it uses Automerge for merging text edits. So it’s a proper CRDT, not just two files merging text diffs.
Conclusion
If you set out to build a local-first application that users have complete control and ownership over, you need something to solve data sync.
Dropbox and other file-sync services, while very basic, offer enough to implement it in a simple but working way.
Sure, it won’t be as real-time as a custom solution, but it’s still better for casual syncs. Think Apple Photos: only your own photos, not real-time, but you know they will be everywhere by the end of the day. And that’s good enough!
Imagine if Obsidian Sync was just “put your files in the folder” and it would give you conflict-free sync? For free? Forever? Just bring your own cloud?
I’d say it sounds pretty good.
