Adventures in REPL implementation
It’s a strange thing to announce, but I wrote Clojure plugin for Sublime Text. Again.
I mean, the previous version worked fine, but it had a few flaws:
- REPL depended on syntax highlighting (yikes!),
- the whole implementation was in a single file,
- it was hard to add REPLs.
So, let’s do it again, almost from scratch, and right this time!
What is REPL?
In a nutshell, REPL consists of three parts: client, server, and communication protocol between them.
Here’s an architectural diagram for you:
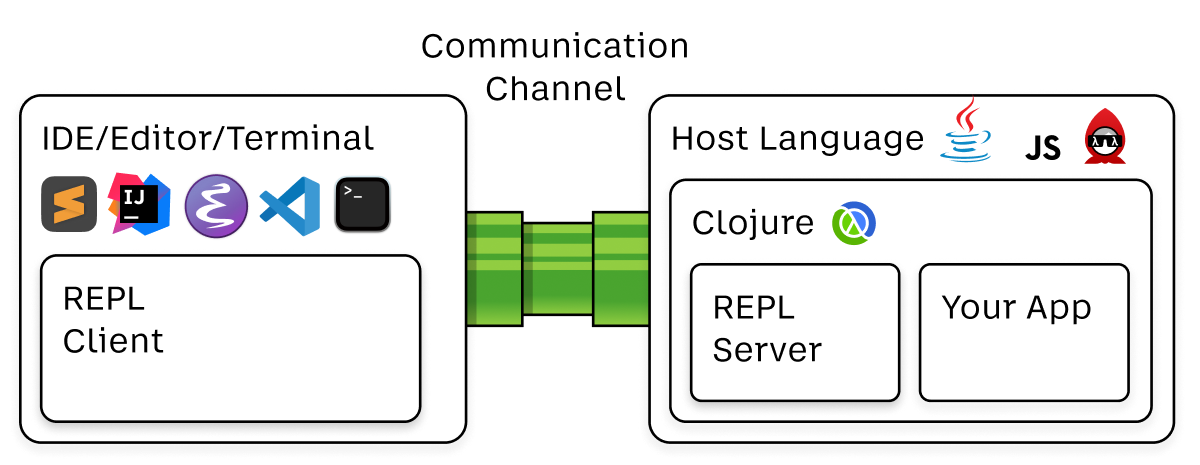
REPL Client
As you can see from the diagram, REPL clients live in a variety of environments dictated by their host: Java for Idea, Python for Sublime Text, JS for VS Code, etc. In my case, it was Sublime Text, so the environment I was stuck with happened to be Python 3.8.
Of course, writing client-server apps is not hard in any language. Unfortunately for us, REPL client needs to be able to read, speak and actually understand Clojure for a few features:
Problem 1: Automatic namespace switching
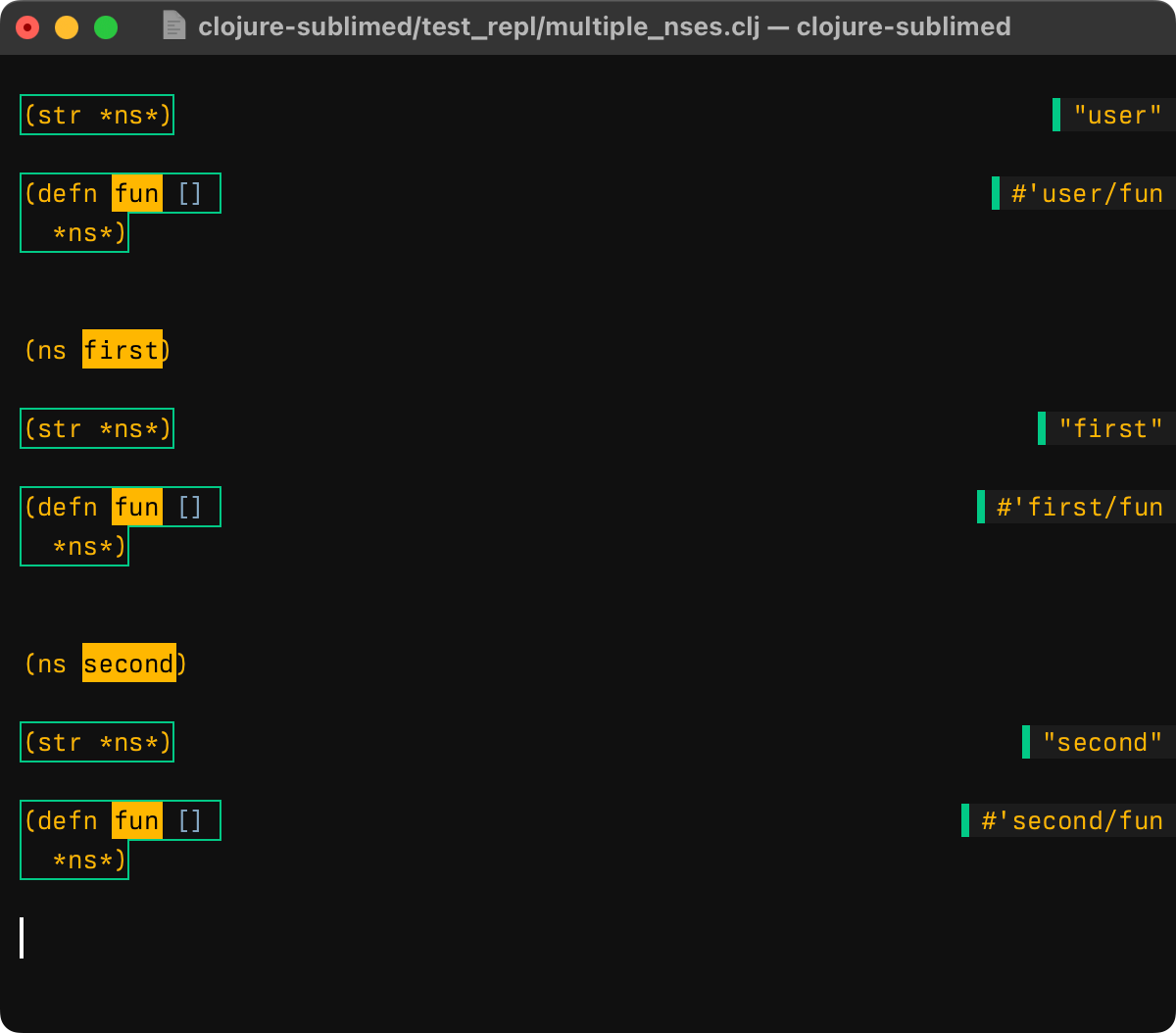
When you go to a file and eval something there, you want it to be run in the context of that file’s namespace. But how to figure out which namespace it is, without parsing Clojure source file?
The level of understanding is non-trivial: there could be multiple namespace declarations, not necessarily at the top of the file:
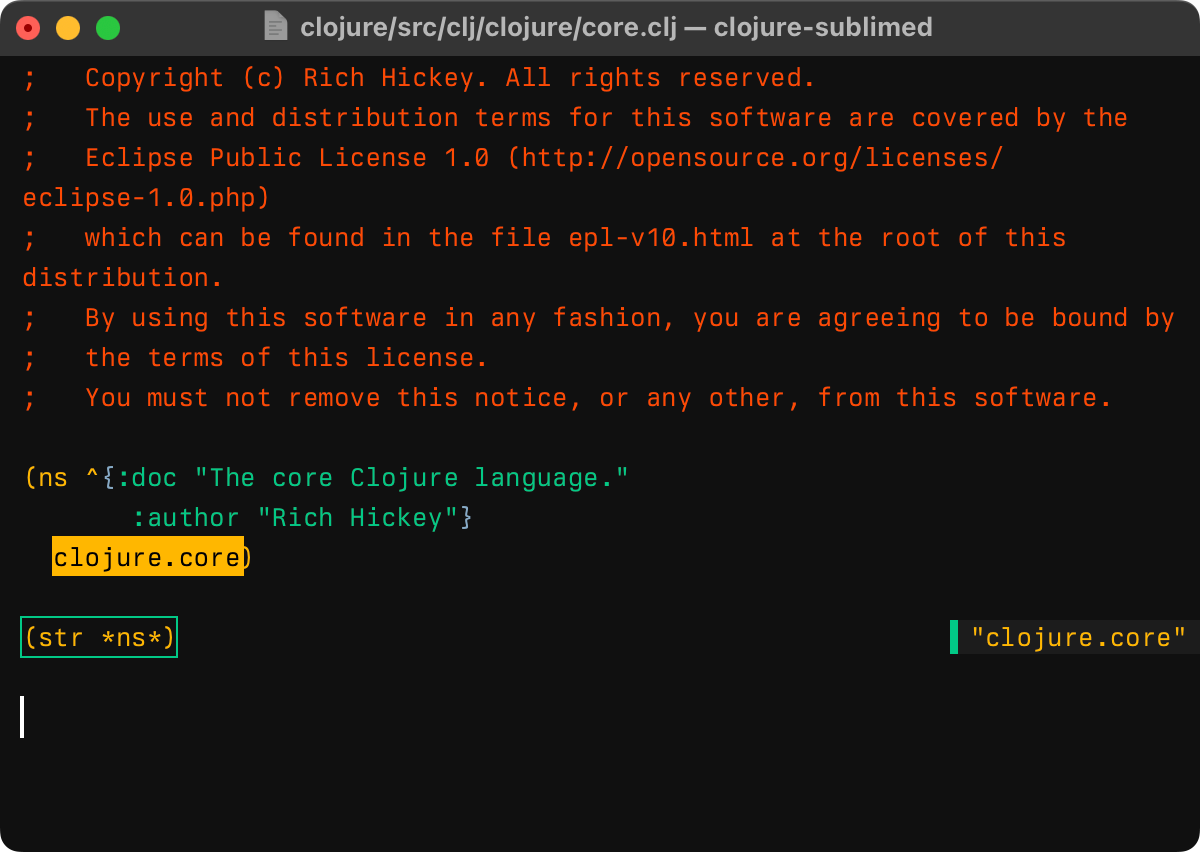
The declaration itself could be complex, too, containing comments and/or meta tokens before the actual name:
Problem 2: Form boundaries
I want a shortcut that evals “the topmost form” around my cursor. To do so, I need to know where those boundaries are.
Notice how I don’t explicitly “select” what I want to evaluate. Instead, REPL client finds form boundary for me:
This is tricky, too. For the very least, you can count parens, but even then you’d have to be aware of strings.
To make things harder, Clojure also has reader tags #inst "2023-02-24", metadata ^bytes b and different weird symbols like @ or #' that are not wrapped in parens but are still considered to be part of the form.
Bonus points for treating technically second-level forms inside (comment) as top-level.
All of this requires a really deep understanding of Clojure syntax.
Problem 3: Indentation and pretty-printing
Clojure Sublimed originally started when I wasn’t happy with what happened when I press “Enter” in Clojure file. Cursor would go to the wrong place, and I (subjectively) was spending too much time correcting it, so I decided to fix that once and for all.
Indentation is not really a REPL concern, but it’s another part of Clojure Sublimed that requires a model of Clojure code.
Indentation logic re-applied to the whole file is formatting, so I got this one for free (both follow Better Clojure formatting rules).
Finally, there’s a question of pretty printing, which is basically indentation + deciding where to put line breaks. Normally this would be done on Clojure side, but doing it on a client has clear advantages:
- you have to send less data when transferring evaluation results (no need to send spaces at the beginning of the line),
- it works for every Clojure REPL the same,
- it can adjust for your current editor configuration instead of some arbitrary server-side number like 80 characters.
Another upside is that I can adjust pretty-printing rules to my liking, of course.
Clojure parser in Python
So, client lives inside your code editor and needs to understand Clojure before it starts communicating with it. Meaning, without Clojure runtime. Meaning, we had to parse Clojure in Python!
This is where things get hard because support for libraries, especially native ones, is not great in Sublime Text. Meaning, pure Python implementation!
I was put off by that task for a long time because it felt enormous. In the first Clojure Sublimed version, I deduced this information from syntax highlighting (Sublime Text already parses your source code for highlighting, and you can kind of access the results of that). But this time I wanted to make things right.
And, in fact, it turned out not to be all that bad! Clojure, like any Lisp, is relatively easy to parse. This is the entire grammar:
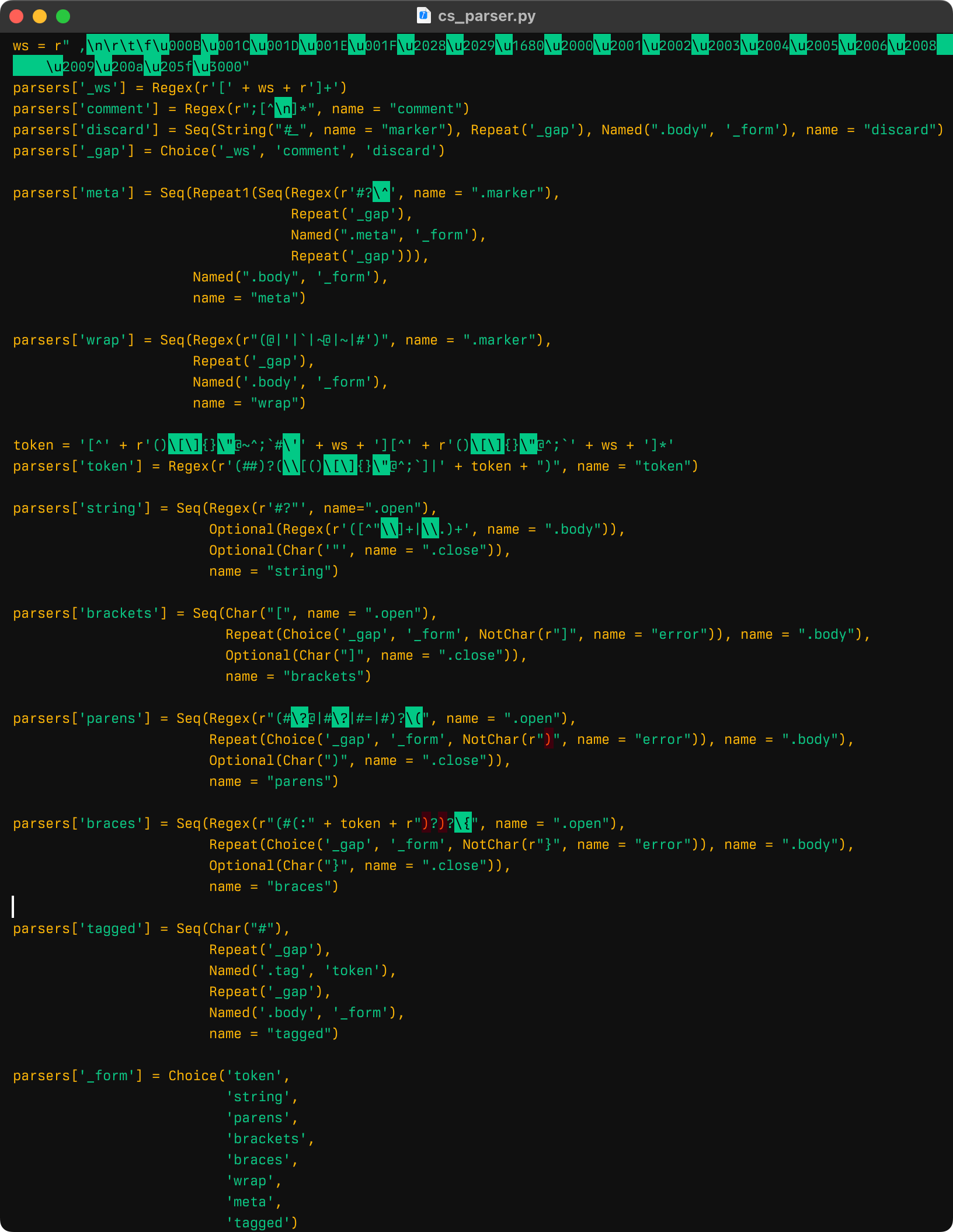
Full source at GitHub.
Some notable details below.
Parser: Cutting Corners
I cut some corners to write less code and get max performance by e.g. not distinguishing between numbers, keywords, symbols — they are all just tokens. It’s probably not hard to add them, but I don’t really need them for what I do, so they are not there.
Parser: Performance
I haven’t spent any serious time trying to optimize the parser. In its current state, it can go through clojure.core (enormous 8000 loc file) in 170ms on my M1 Mac.
Clojure itself does the same in roughly 30-50 ms, though, so there’s definitely potential for improvement.
Parser: Incrementality
Should be possible one day :) So far performance is good enough to re-parse on each “enter” keypress.
Parser: Testing
Parse trees could be quite hard to navigate, and twice as hard to compare.
Parsing also requires a lot of tests to get everything right and to avoid regressions. So having a nice and ergonomic way to write and inspect tests was super important.
I ended up copying test syntax from tree-sitter.
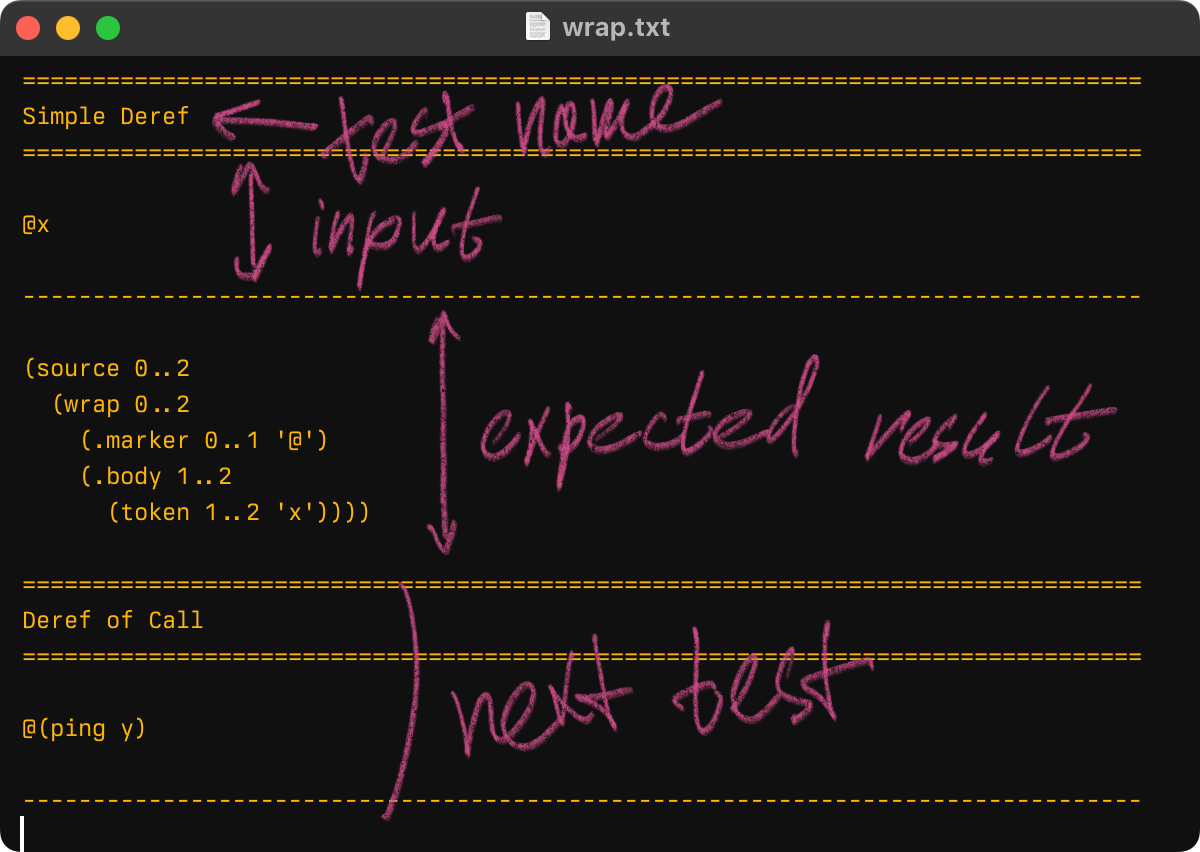
Test runner just compares the actual result with the expected one string-wise and if they are different, reports an error in a nice to comprehend table:
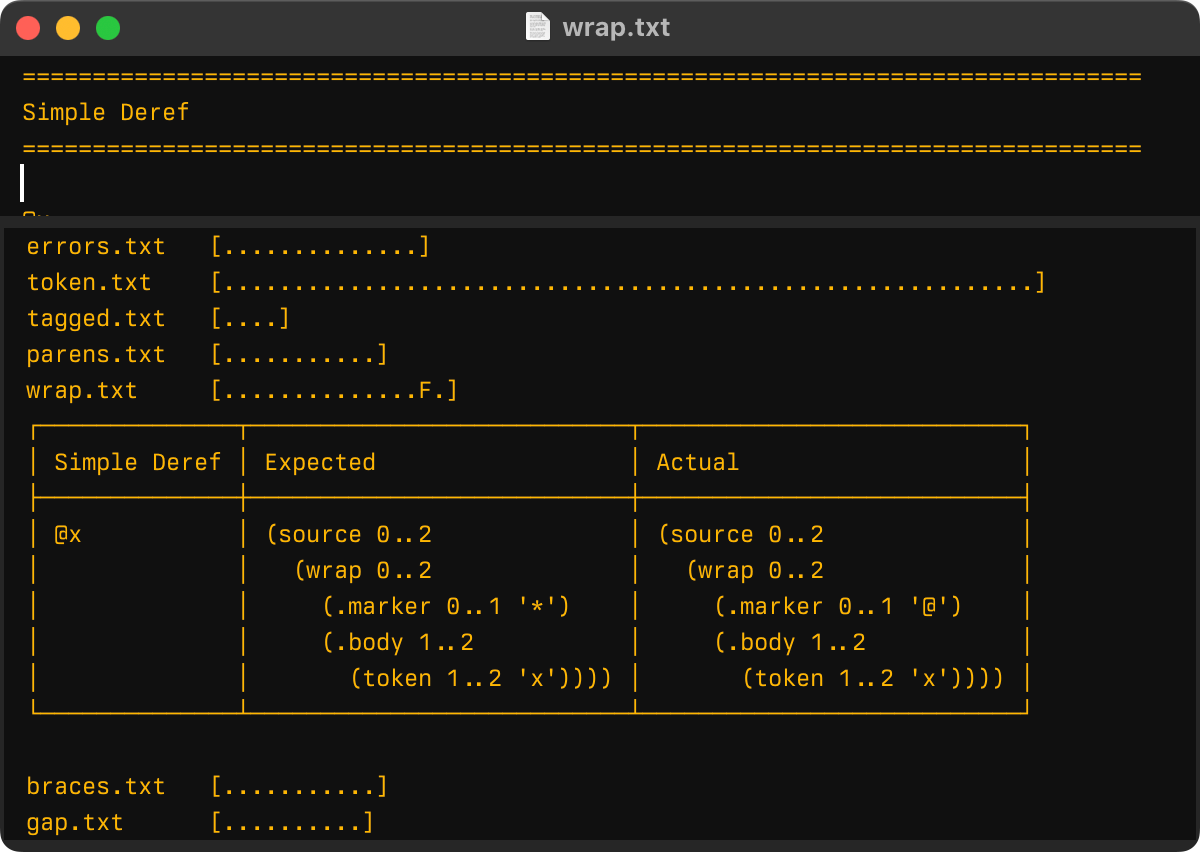
Having this early on saved me a ton of time and I am 100% happy I made that investment.
Parser: Error recovery
Parsing valid Clojure code is quite easy. But code in the process of editing is not always correct, even syntactically. That means that our parser has to work around errors somehow!
So I decided to see how people smarter than me do it and found this:
In the yacc and bison parser generators, the parser has an ad hoc mechanism to abandon the current statement, discard some parsed phrases and lookahead tokens surrounding the error, and resynchronize the parse at some reliable statement-level delimiter like semicolons or braces.
So yeah, I guess no beautiful theory on error recovery.
For our purposes, though, it was quite simple: see something that you don’t understand? That must be an error. Most stuff gets consumed as a symbol or a number, though, so these were rare.
We did accept some invalid programs as valid, but that’s okay for our use case: find expression boundaries, throw it over the fence, and let Clojure work out the rest of the details.
Parser: Accidentally quadratic
One funny thing happened during testing: I noticed that sometimes the parser was becoming ultra-slow on moderately-sized files. Like, seconds instead of milliseconds. That means I had quadratic behavior somewhere.

And that was indeed the case. The first version of the parser, roughly, was parsing parens/brackets/braces like this:
Seq(Char("["),
Repeat(Choice('_gap', '_form')),
Char("]"))This basically means: if you see an opening bracket, consume forms and whitespace inside as long as you can, and in the end, there must be a closing bracket.
Well, what if it’s not there? That means it wasn’t a 'brackets' form in the first place! This is technically correct, but also means we have to mark the opening bracket as an error and then re-parse everything inside it again. That’s your quadratic behavior right here!
A simple change got rid of this problem:
Seq(Char("["),
Repeat(Choice('_gap', '_form')),
Optional(Char("]")))Technically, this accepts incorrect programs. In practice, though, it works exactly as we need for indentation: we only care about opening parens up to the point of the cursor and don’t really care what happens after it.
Parser: Conclusion
Writing the parser was very fun! So many little details to figure out and get right, but in the end, when everything snaps into place, it’s so satisfying!
I also now understand why Lisps were so popular back in the day: they are really made for ease of implementation. Hacking together an entire parser from scratch in a weekend — can you imagine it for something like C++ or Python?
Anyways, if you need Clojure parser in Python, take a peek at my implementation — maybe it’ll help you out!
Protocol
Let’s move to the second part of our architecture: the communication channel.
How does a server talk to a client? Die-hard Clojure fans would answer immediately: EDN! But it’s not that simple.
Yes, EDN is the simplest thing for Clojure users. But what about the rest of the world? Don’t forget that on the other side there’s an arbitrary platform and, despite Rich’s best efforts, EDN is not as widespread as we’d like.
Just send... forms?
This is what clojure.core.server/repl does. Basically, it’s the same interactive experience as with command-line REPL, but over a socket:
Not machine-friendly at all.
Half-EDN
Type in forms, receive EDN-formatted output. clojure.core.server/io-prepl does that:
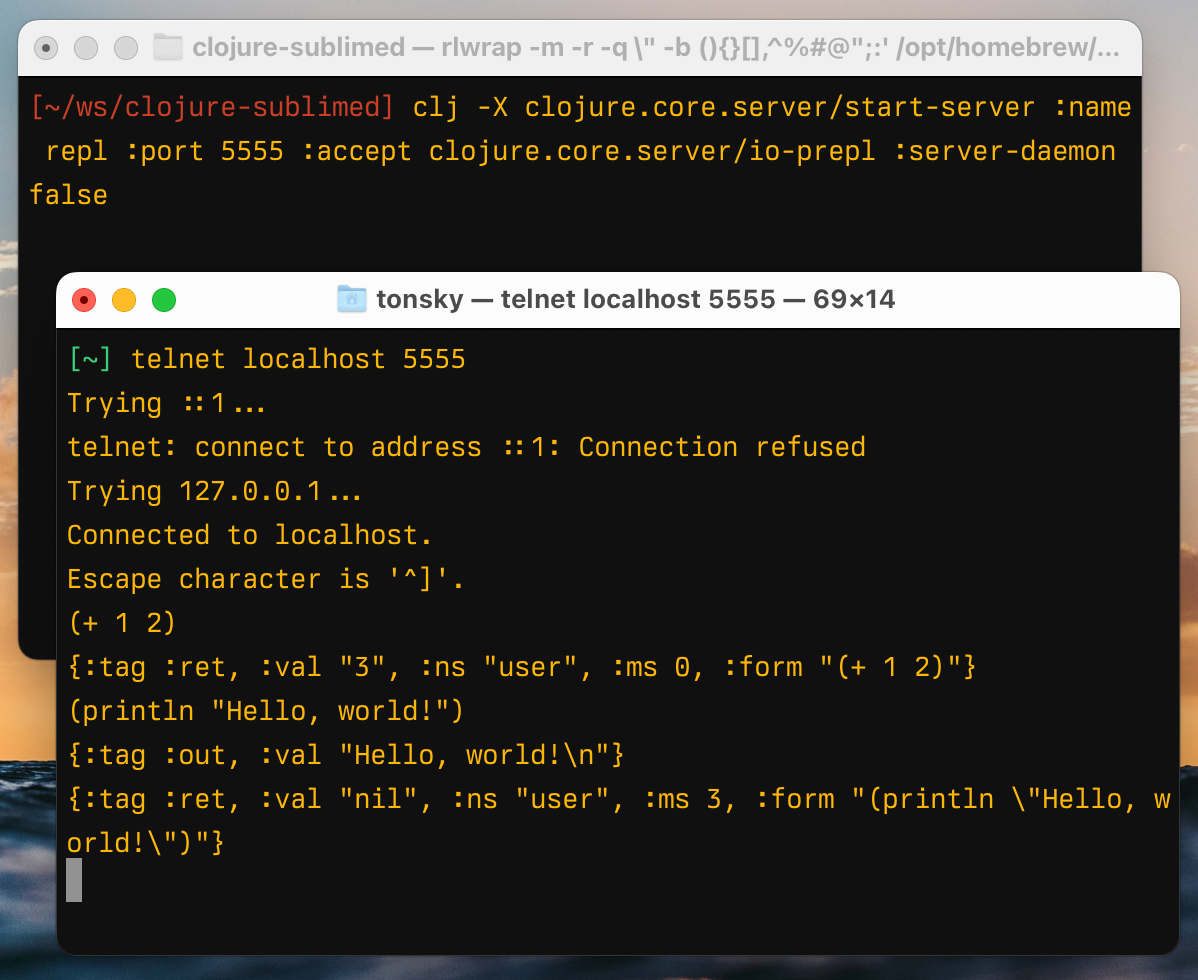
Half machine-friendly and you have to be able to parse EDN.
JSON + EDN
Following the half-EDN example, our protocol doesn’t have to be symmetric, either. If we make ease of implementation our first priority, we can go crazy:
- Client sends EDN, which is easy to parse in Clojure,
- Server sends JSON, which could be parsed with Python stdlib.
Not elegant, but, you know, gets the job done. In both cases, messages are simple enough to be composed with string concatenation, so we only really care about parsing.
The only problem I have with this solution is that it offends my sense of beauty.
Bencode
nREPL also had this problem: a common denominator for multiple clients in all possible languages. Their answer? Bencode.
Bencode is a simple binary encoding developed for BitTorrent. And when I say simple, I mean very simple. Yes, simpler than JSON.
This is the entire Bencode grammar:
number = '0' / '-'? [1-9][0-9]*
int = 'i' number 'e'
list = 'l' value* 'e'
dict = 'd' (value value)* 'e'
string = length ':' bytes
length = '0' / [1-9][0-9]*
value = int / list / dict / stringAnd here are some actual messages when communicating with nREPL server:
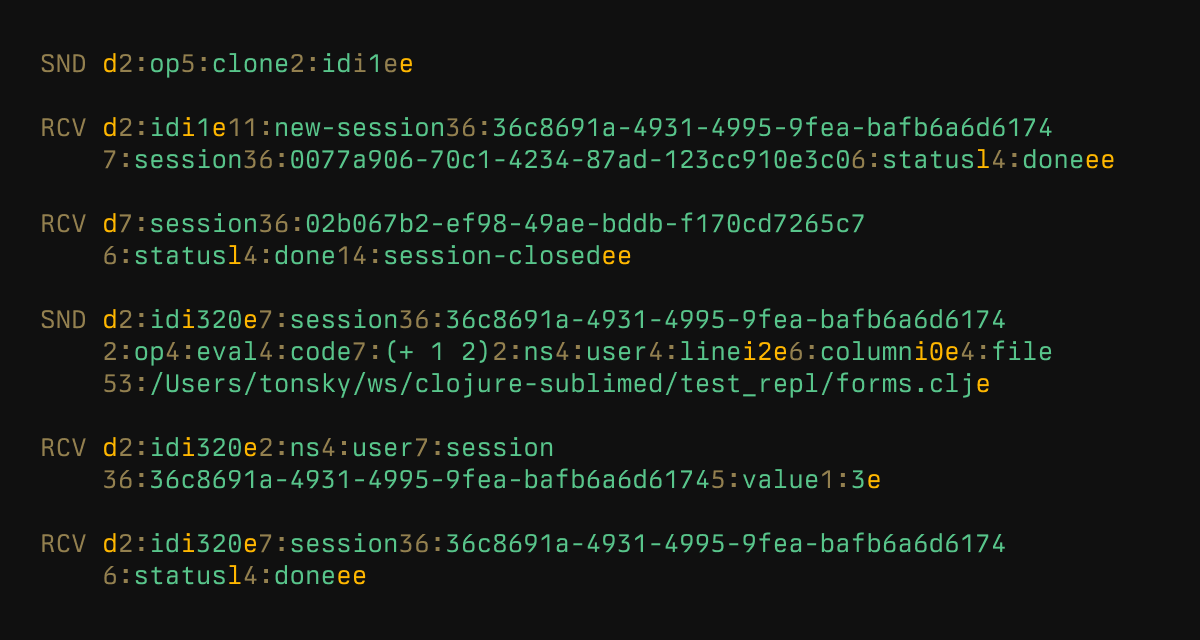
Bencode is not supported out of the box by either Python or Clojure, but implementation easily fits in 200 LoC.
Problem? It’s binary. Unfortunately, you can’t run binary protocols on top of Socket Server, only the text ones. So to be able to use bencode you’ll have to start your own server.
Clojure Sublimed uses bencode for connecting to nREPL servers.
MessagePack
MessagePack is beautiful, exactly as I would’ve designed a compact binary serialization format. Everything is length-prefixed, super-simple to implement and you can support only parts that you actually use.
But it’s binary, so can’t be used on top of Socket Server, and I’m not prepared to write my own REPL server yet.
Consider voting for this issue and the situation might change! I believe Clojure deserves binary REPLs as much as text-based ones.
EDN both ways
A lucky coincidence saved me here. Remember the first part where I was writing Clojure parser? Guess what? Since EDN is a subset of Clojure, my parser also can parse EDN well enough to understand REPL server responses!
This is what my upgraded Socket Server REPL looks like on the wire:
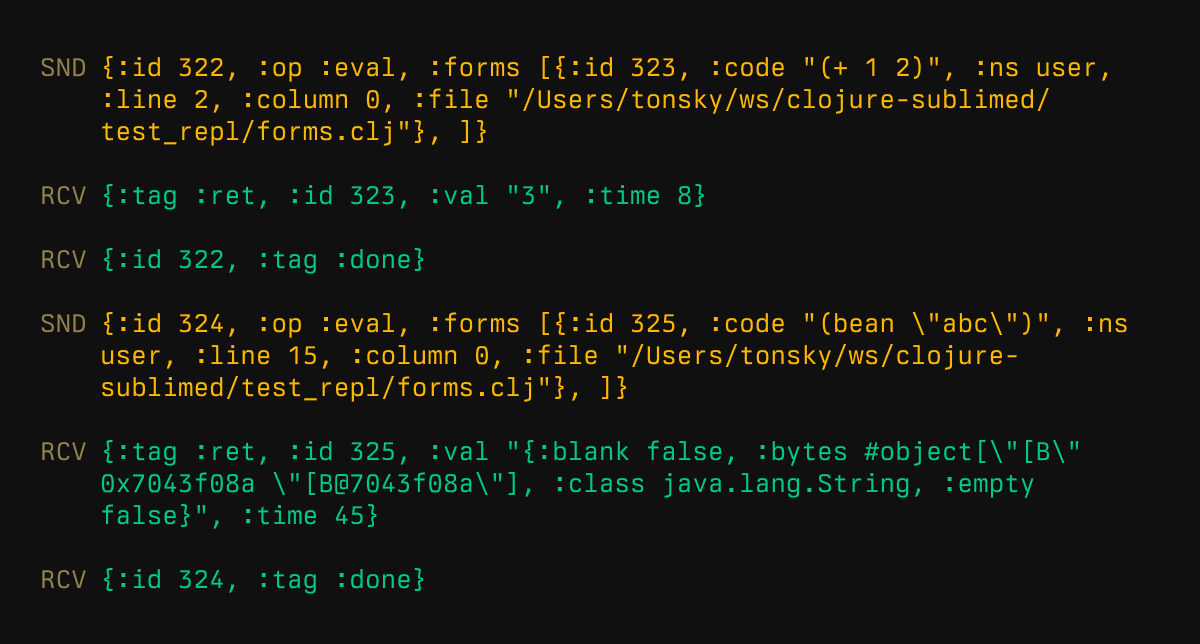
Yes, it looks like nREPL over EDN.
No, it’s not exactly nREPL, it’s subtly different (see the server breakdown below), so there can be more chaos.
Did I invent another wheel? Maybe. But it’s a good wheel and it suits my needs well.
A note on message boundaries
The tricky part of EDN-on-the-wire? How to separate messages.
Clojure has a streaming parser: it consumes data from socket char-by-char and parses it as it goes until it reads a complete form. That’s why, for example, you can’t evaluate something like (+ 1 2 in the REPL, no matter how many times you press Enter.
But my Python parser wasn’t streaming :( You give it a string, it’ll parse it. But it can’t tell you how much of that string to read from a socket. If only TCP was message-oriented — one can dream!
So the solution was... split on newlines :) Lucky for me, the default Clojure printer escapes newlines in strings, so it can’t occur inside the message.
EDN doesn’t exactly forbid newlines, though, so let’s hope they won’t suddenly start to appear one day.
Server
Finally, the third and final part of our architecture: the server. When I only started learning about Clojure and Lisps, I imagined that REPL is literally that:
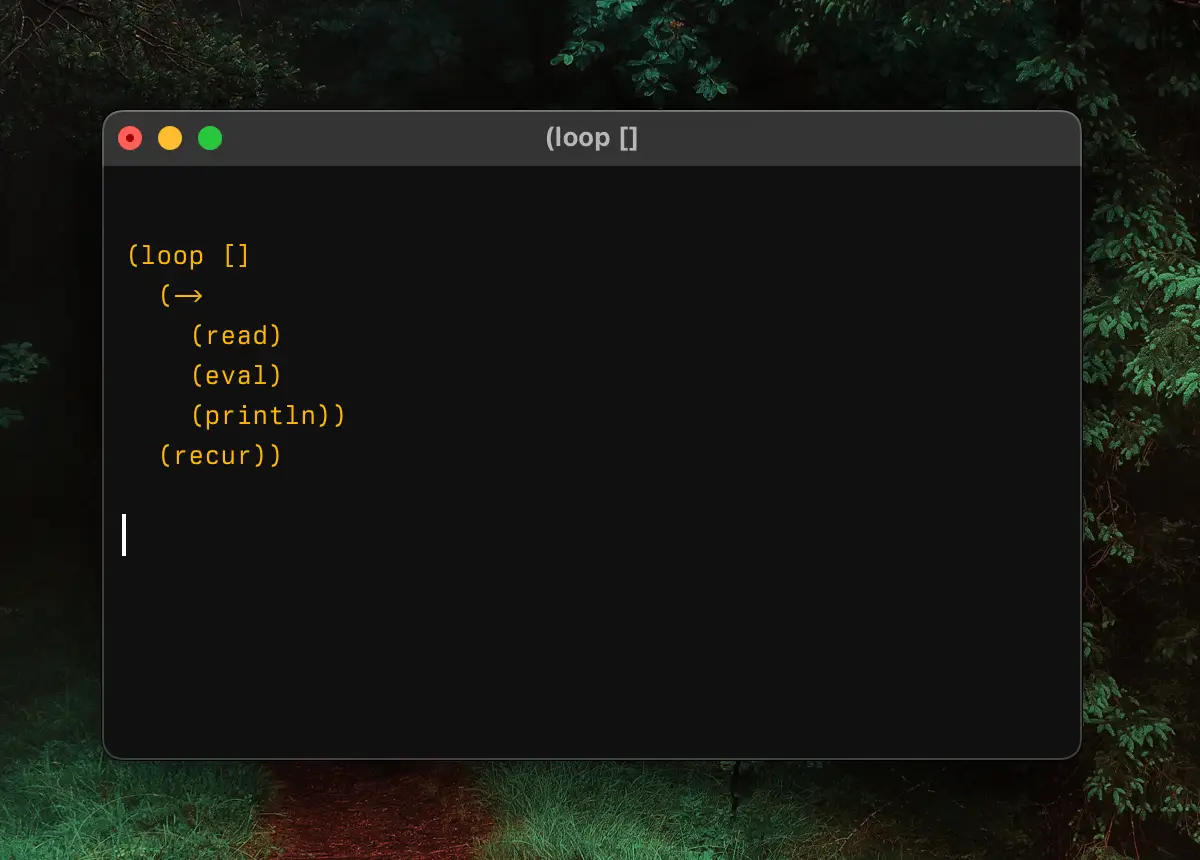
Because of that ignorance, it was hard for me to understand why there are different REPL implementations and why you need to “implement” REPL at all.
Let’s go from the simplest case to more complex ones.
Naive REPL
Funny enough, the function I showed you above works:
It’s very fragile, though: it’ll die on the first exception.
It also doesn’t do many things which you’ll see more sophisticated REPLs provide.
clojure.main/repl
This is the REPL you get when you run clj or clojure command-line utility.
It works essentially the same, but does a little bit of extra work for you:
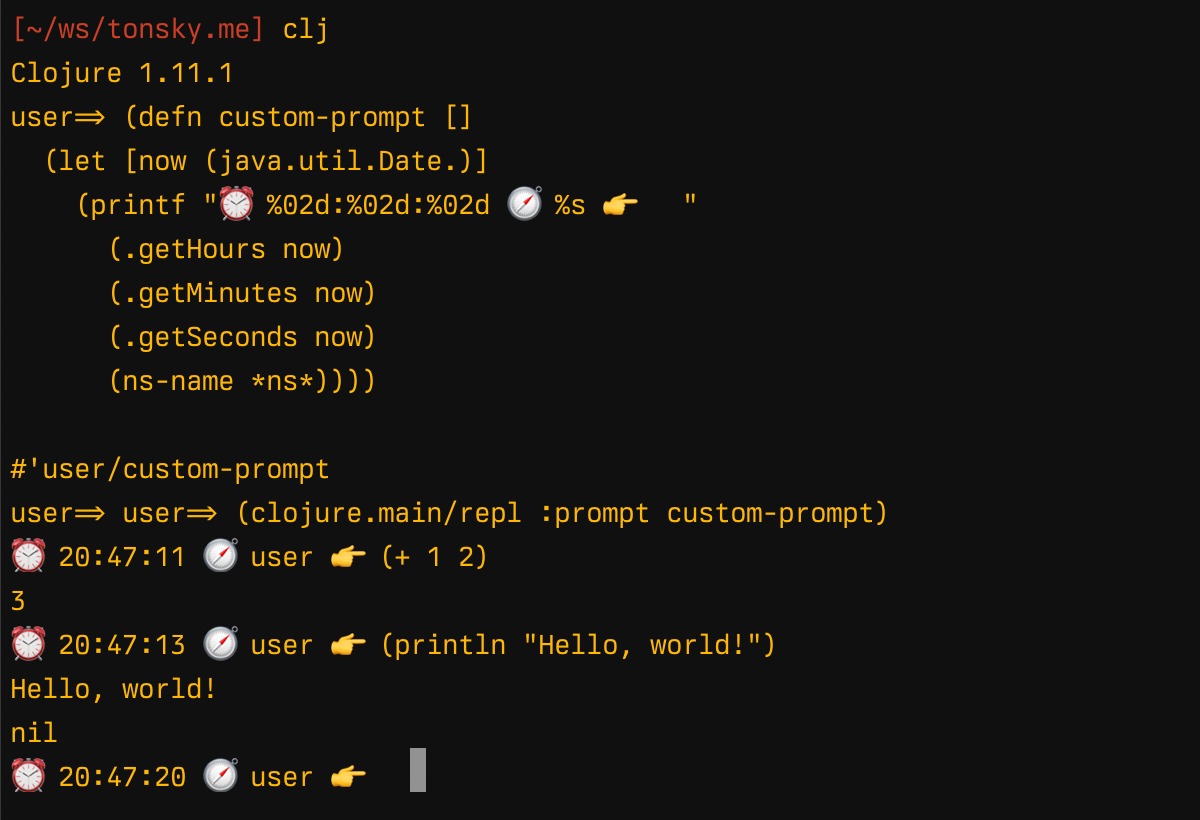
First and most notably, it prints a command prompt that displays the current namespace:

Which you can actually customize to your liking:
Then, it catches and prints exceptions, so your REPL doesn’t die when you make a mistake:
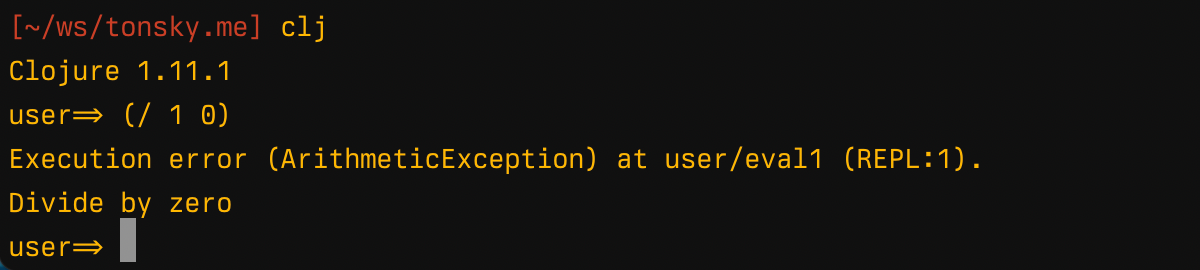
It also stores the last calculated values in special *1..*3 dynamic vars and the last exception in *e. These variables do not exist outside of REPL:
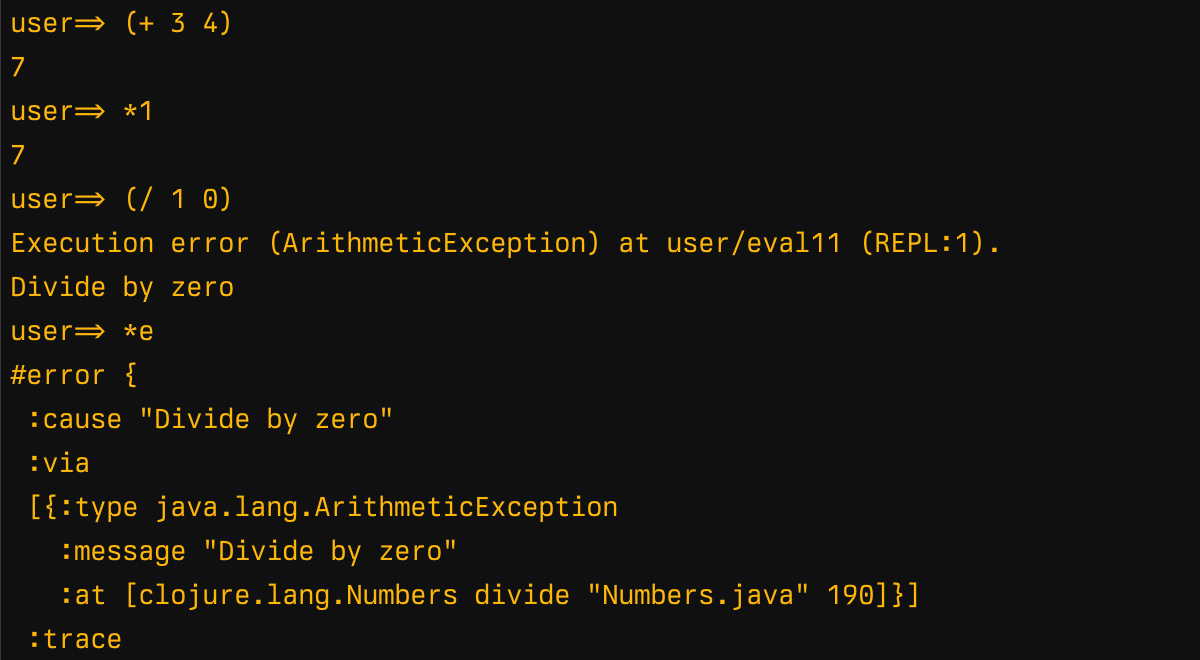
Another convenience that default REPL does is requiring some stuff from clojure.repl and clojure.pprint:
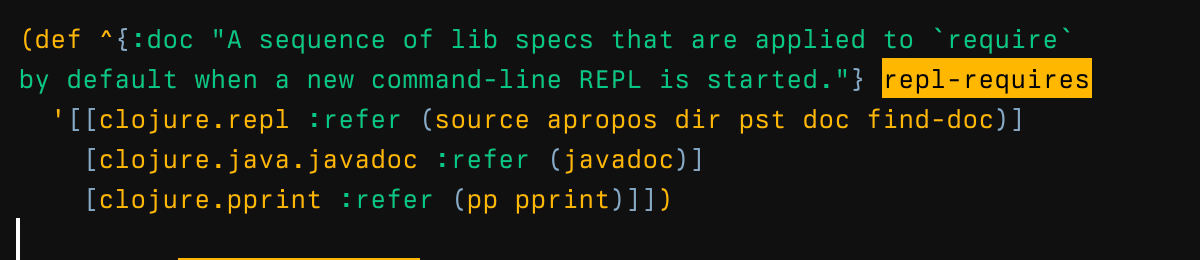
Were you wondering where (doc) in REPL comes from? Now you know.
Finally, it isolates vars like *ns* or *warn-on-reflection* so that when you set! them in your REPL session it doesn’t alter their root bindings.
Quite a bit of nuance, huh? With all that, clojure.main/repl is still considered very basic. There’s more stuff you can do!
clojure.core.server/repl
Basically the same as main/repl, but for the access over the network.
The only difference is output. If your entire program IS the REPL, you don’t have to do anything special with it.
But if you are connecting dynamically to a working program, things get trickier. Where should (println "Hello") print?
If it prints to stdout of the process, you won’t see it in your REPL. It’ll go to wherever the server process redirects its standard output.
So what Server REPL does is it redefines *in*/*out*/*err* to socket streams instead of process’s stdout and sends to you what you print over the network. Everybody gets their own stdout!
Really tricky stuff to figure out, but essential to understand if you consider yourself an advanced Clojure REPL user.
The rest is the same. Server REPL literally calls into main/repl after rebinding *in*/*out*/*err*.
clojure.core.server/io-prepl
pREPL is Clojure team’s answer to nREPL and critique that Clojure Socket REPL is not machine-friendly. It’s basically server/repl but with EDN-formatted output:
pREPL consumes raw Clojure forms but outputs EDN-structured data.
In terms of what it does for you, it also formats exceptions (not in a Clojure-aware way, unfortunately) and synchronizes your output so that two threads can’t print simultaneously. But that’s about it.
The main problem with pREPL is that it’s based on EDN and, thus, aimed at Clojure clients first and foremost.
nREPL
nREPL is a third-party server started by Chas Emerick and lately adopted by Bozhidar Batsov. It’s a separate library that you have to add to your project and start the server yourself.
As Rich Hickey put it, ”nREPL is not a REPL, it’s remote evaluation API”. He’s not wrong, but I think that’s exactly what tooling authors need: remote eval API, not interactive console.
First, nREPL is machine-friendly both ways. It receives bencode-d data and sends bencode-d data back.
Second, it walks an extra mile for you:
- Its
evaloptionally accepts file name and position in that file, so that stack traces would contain the correct position. - It limits the size of the output to a user-provided threshold, saving you from printing infinite sequences which are not rare in Clojure.
- It provides interruption for already executing evals.
- Some of its functions like
lookupandload-filesolve problems that their Clojure alternatives don’t. - Some are just conveniences like
completions. - It’s extensible, allowing you to create your own operations.
All this stuff is very useful and doesn’t come “naturally” with naive REPL implementations.
The downside? You need to add nREPL server dependency to your app. It also has a noticeable startup cost (~500ms on my machine).
Extended nREPL
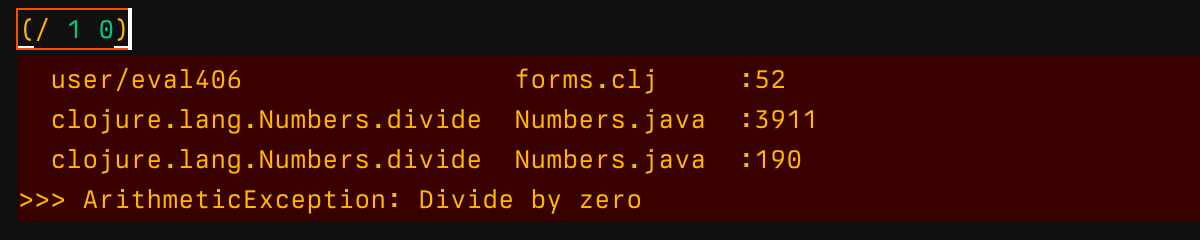
Since nREPL is extensible, one can extend it to do even more. That’s what the first version of Clojure Sublimed did and still does. Including:
- Formating stack traces in a Clojure-aware way and sending them back with errors:
- Parallel evaluation and execution time:
It worked well for me for 1.5 years, but still, you know, nREPL dependency, startup time, NIH syndrome. I wanted to give REPL a shot on my own.
REPL, upgraded
Even the simplest REPL still has the full power of Clojure in it! We can start with something very basic, like server.repl, send our own server’s code to it first thing after connecting, and then take control over stdin/stdout and start serving our own protocol with our own execution model.
This is called “upgrading” your REPL and that’s how Christophe Grand’s Unrepl works, for example. The beauty of it is zero dependencies: you only need Clojure and nothing more. Everything you need you bring with you.
In our case, it looks like this. First, we send a lot of Clojure code (unformatted, because machine doesn’t care):
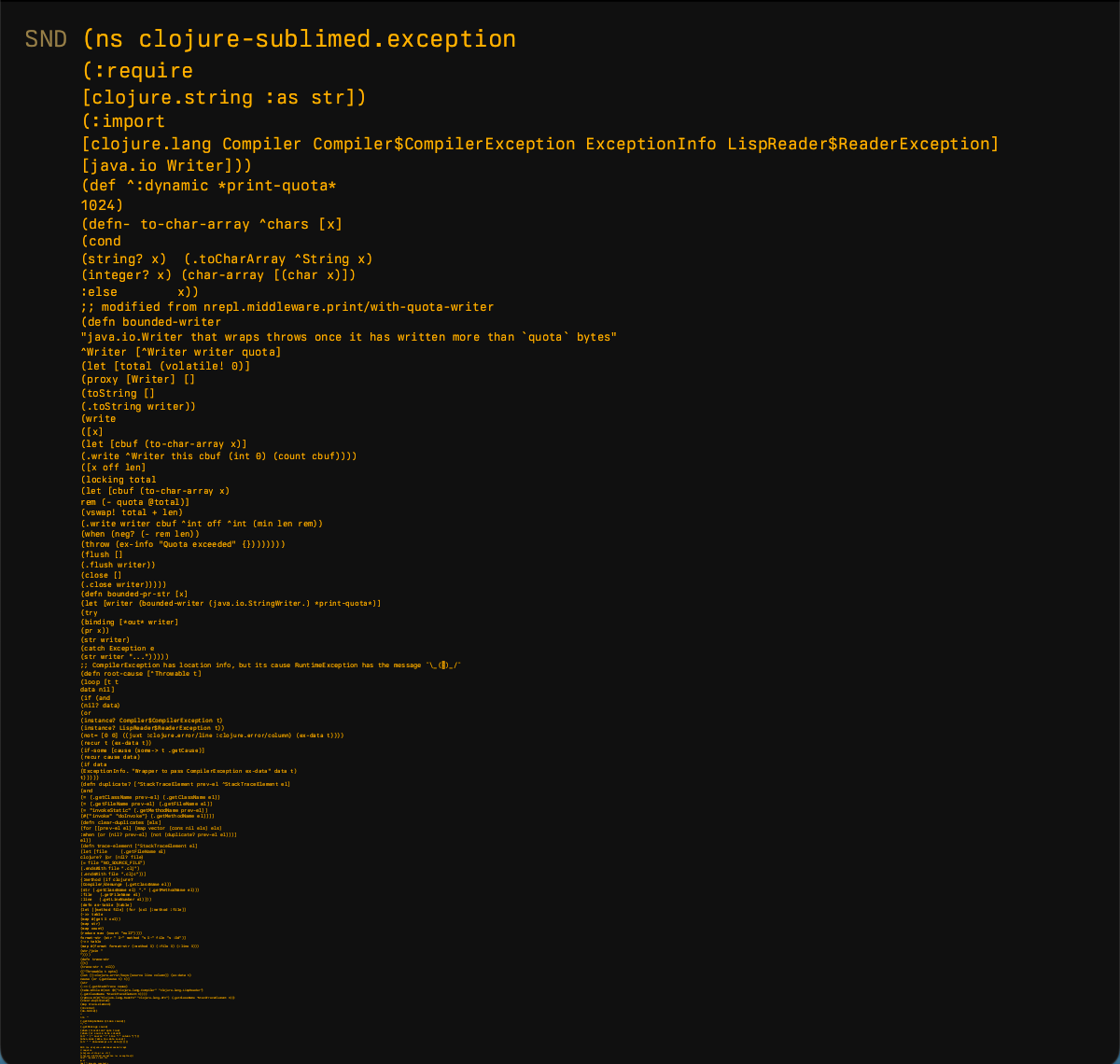
Then, we receive this:
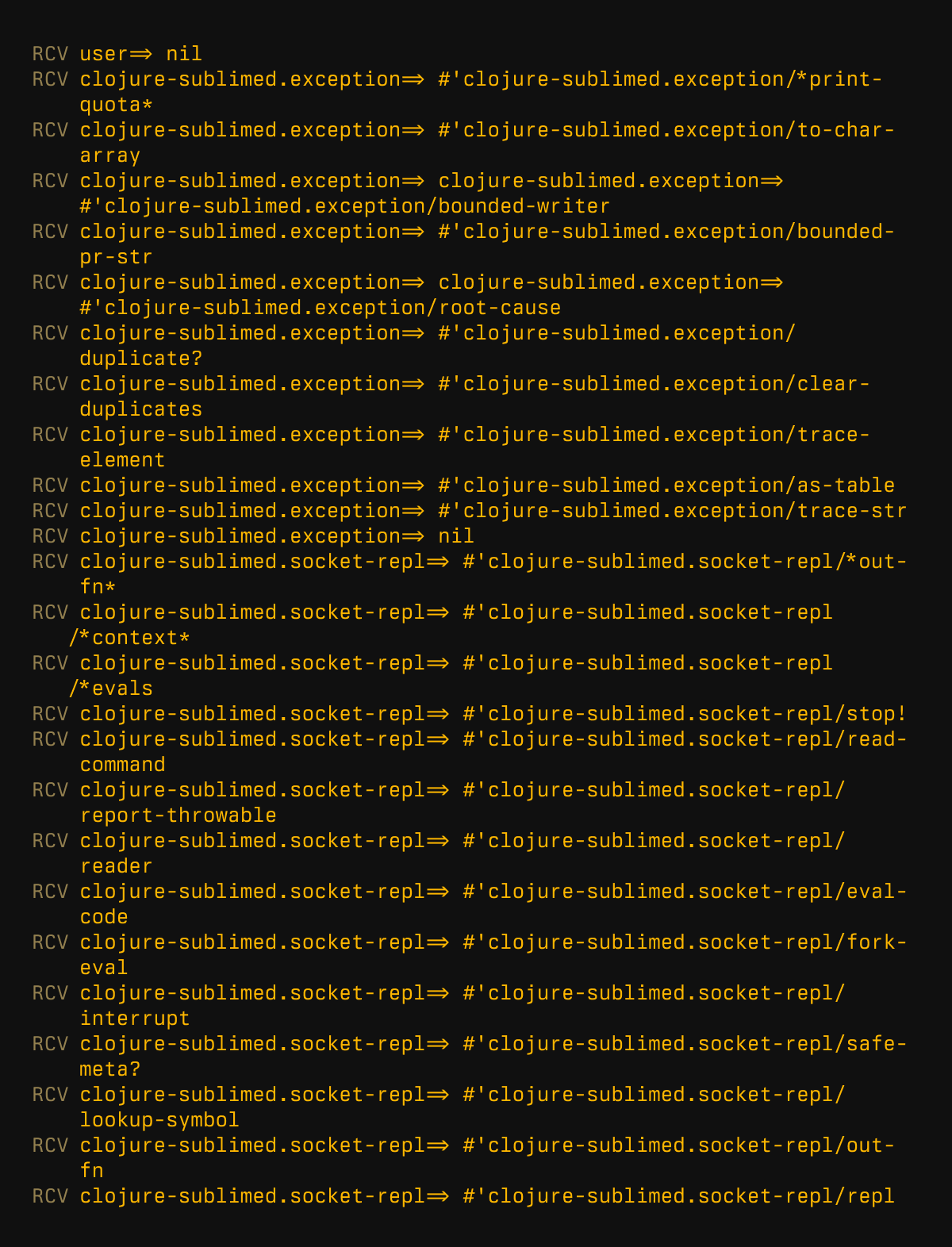
Which basically means “Yes, I’ve heard you”.
This is all happening inside basic server/repl. It looks messy because it was designed for human consumption (eye-balling), and we don’t even try to interpret it. We just cross our fingers and hope everything we sent works.
At this point, we’re ready to “upgrade” our REPL. This is how we do it:

(repl) is a function we defined in our initial payload. {"tag" "started"} is the first message of our own protocol. I really, really, really hope here that it will not be messed up by other output (printing in Socket Server is not synchronized, and everyone who worked with Clojure REPL in the terminal knows how often it messes up your output).
After the client sees {"tag" "started"} somewhere in the socket, it considers the upgrade to be finished and now works in our own nREPL-like EDN-based protocol.
Clojure Sublimed REPL Server
Our upgraded Clojure Sublimed REPL does all the same basic stuff that nREPL does. The only practical difference for clients is batch evaluation: send multiple forms together (e.g. when evaluating the whole buffer) and get separate results for each one.
nREPL eval-buffer:
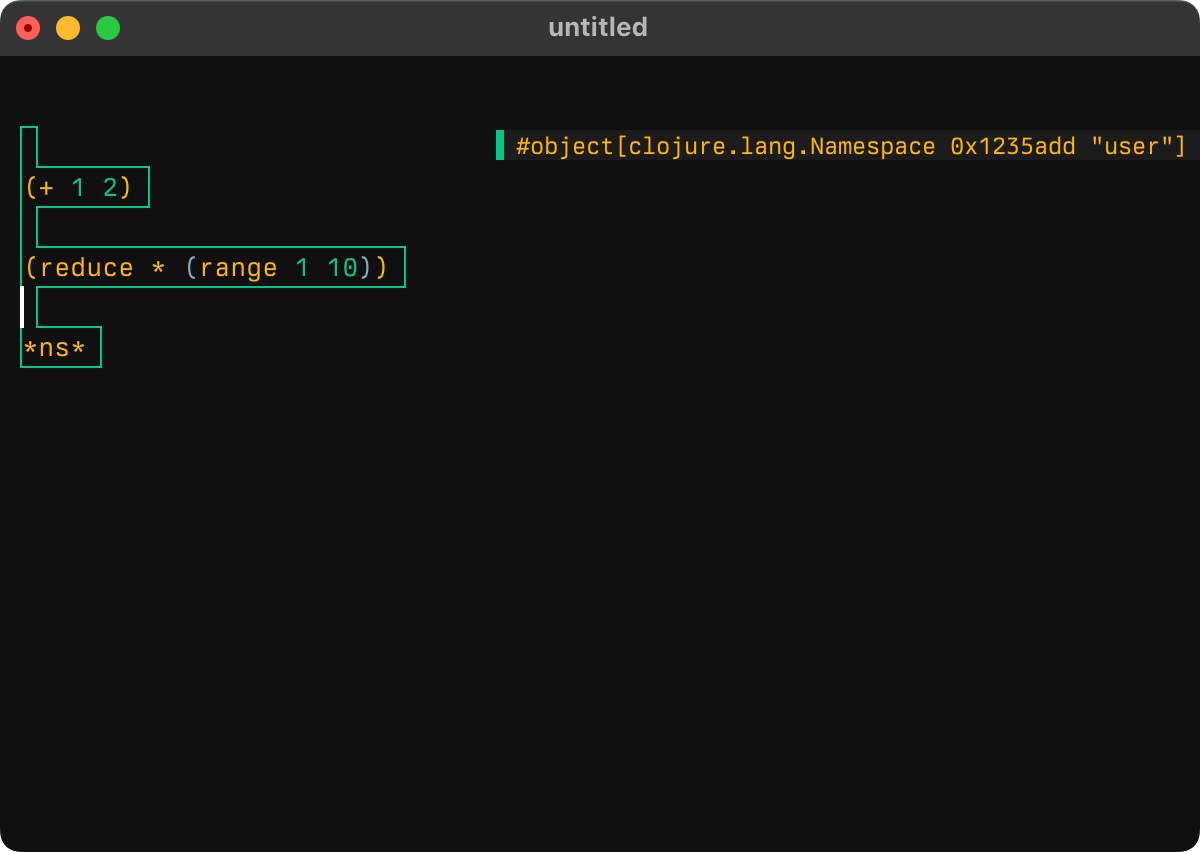
Clojure Sublimed eval-buffer:
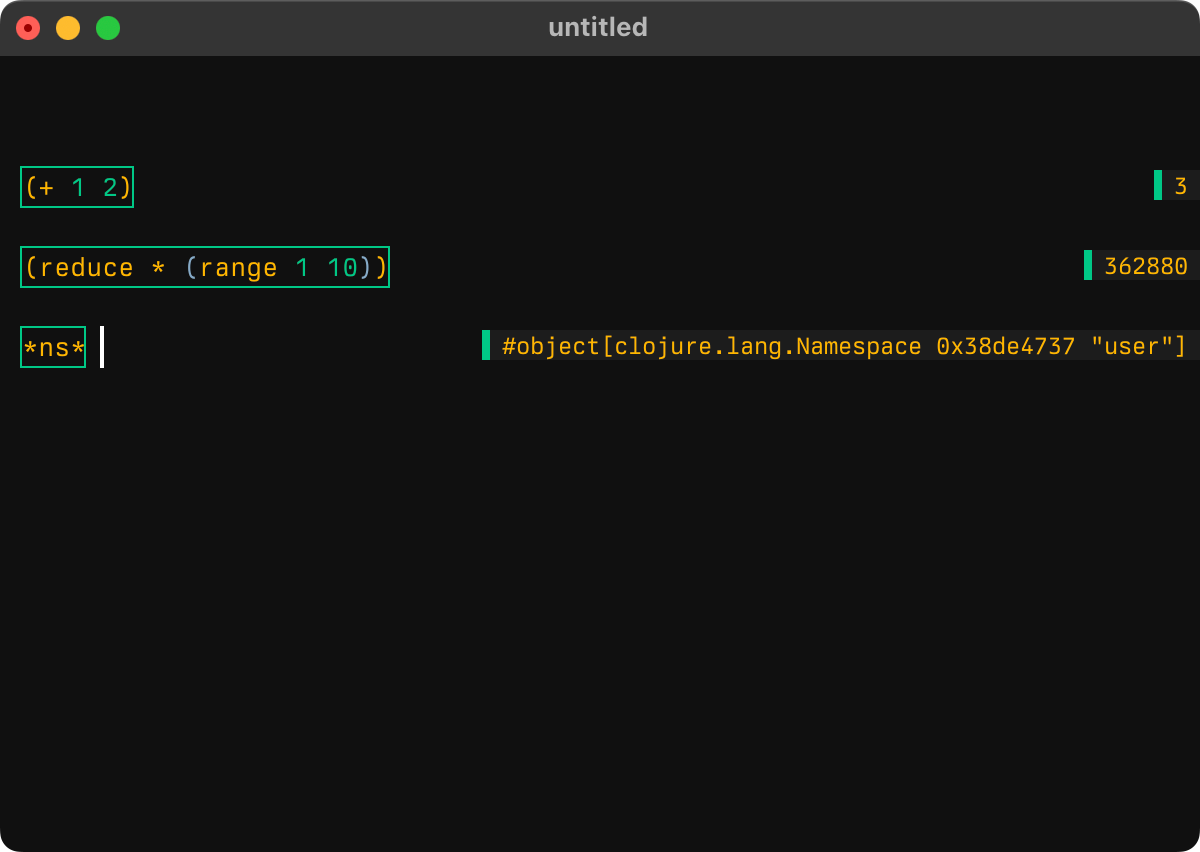
Under the hood, though, it’s a completely new REPL. It sits on top of Socket Server, yes, but it has its own evaluation model and its own protocol. It’s clean, minimal, fast to load, and works much better with Clojure Sublimed client than nREPL.
I don’t want to release yet separately from Clojure Sublimed (yet?), but, you know, take a peek at the implementation anyway.
Your own REPL!
The original version of Clojure Sublimed (client) was organized quite poorly and adding new REPLs was problematic.
New, refactored Clojure Sublimed was designed to be easy to extend. Out of the box, we ship with these now:
- JVM nREPL which installs a few extra middlewares.
- (new) Raw nREPL for non-JVM environments (babashka, etc).
- Shadow-CLJS nREPL which (now) adapts better to shadow-cljs quirks.
- (new) JVM Socket REPL which works on top of bare-bone Clojure Socket Server.
And there could be more! If you are interested, let me know, or, better, jump in with a PR! I promise it should be much easier now. I even wrote docstrings everywhere at some places :)
Conclusion
So, Clojure Sublimed v3 is out there. To sum up the major differences:
- REPL doesn’t depend on syntax highlighting,
- new JVM Socket REPL,
- easier to add new REPLs,
- client-side pretty-printer,
- faster indenter and formatter.
As always, you can get the new version in Package Control or on Github:

Let me know what you think! Issues are open :) And happy Clojur-ing!
You were going to ask anyway
Color scheme: Niki Berkeley.
The font on screenshots: Berkeley Mono.
