Blind Spot in Dependency Management
Let’s talk about one overlooked aspect of dependency management. I know what you would say, wait a minute, dependency management, the whole domain is a trivial problem that tricks everybody into overthinking overcomplicated solutions.
And I’d agree with you. Not.
But that’s not the point. What worries me is that while a lot of effort goes into fetching the right version of a library, close to none is spent on convincing me why I should want it in the first place.
Some tools fail to even fulfill the first part of the promise and will only fetch you some version, effectively removing the second problem for you (if you don’t control what version you are getting you won’t be troubled choosing one).
Yet, some of us have slightly higher standards than that. Let’s assume that our tool is smart enough to fetch exactly what we’ve told it to. All is fine for a while, until, two years in a project, you ask yourself if something positive has happened with the libraries you started using back then. Maybe you’re lucky and your tool can even compile a list of outdated versions for you:

But that’s not the problem. How do you decide, in each particular case, if you should type “yes” or “no” there? Guessing? Hard guessing? Is there a threshold? If you’re more than 3 minor versions behind, you upgrade, otherwise, you let it be? Scientifically controlled and totally fair coin toss?
Sometimes it’s easy. Don’t touch what’s working, they say. But you only think it is.
Say, you need a specific bug fixed, and people behind the library use an issue tracker, and you even happen to know the ticket id. Now, if that issue tracker is something punk and unpopular, like Github, strangely, it won’t help you at all. You can’t figure out in which version it was fixed given an issue or pull request id. Even if you’re a very responsible maintainer and do everything right. Lesson #1: don’t host your libraries on Github, kids.1
Luckily, solid time-tested full-package solutions like JIRA give you a “fix version” number (if you can find it on issue page). Problem is, you can’t just upgrade to that version. You bug was fixed in 4.7.8, you’re on 4.3.2, god knows what else will that upgrade bring.2 If I were you, I’d pass on that. I once tried to bump AWS client from 1.8 to 1.10, and they renamed, like, every class inside. I’d rather start a new project from scratch than upgrade my libraries.
“That’s why JIRA can generate you a changelog!”
Can it?
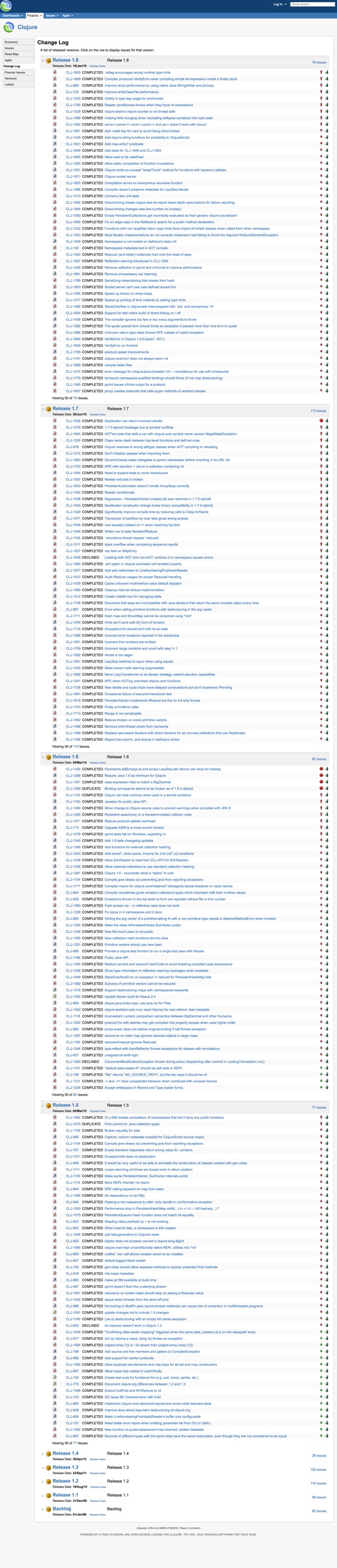
Sure it can. Good luck drilling through it. Also good luck finding out about changes people made outside of tickets.
“That’s why there’s a commit log!”
Is there?
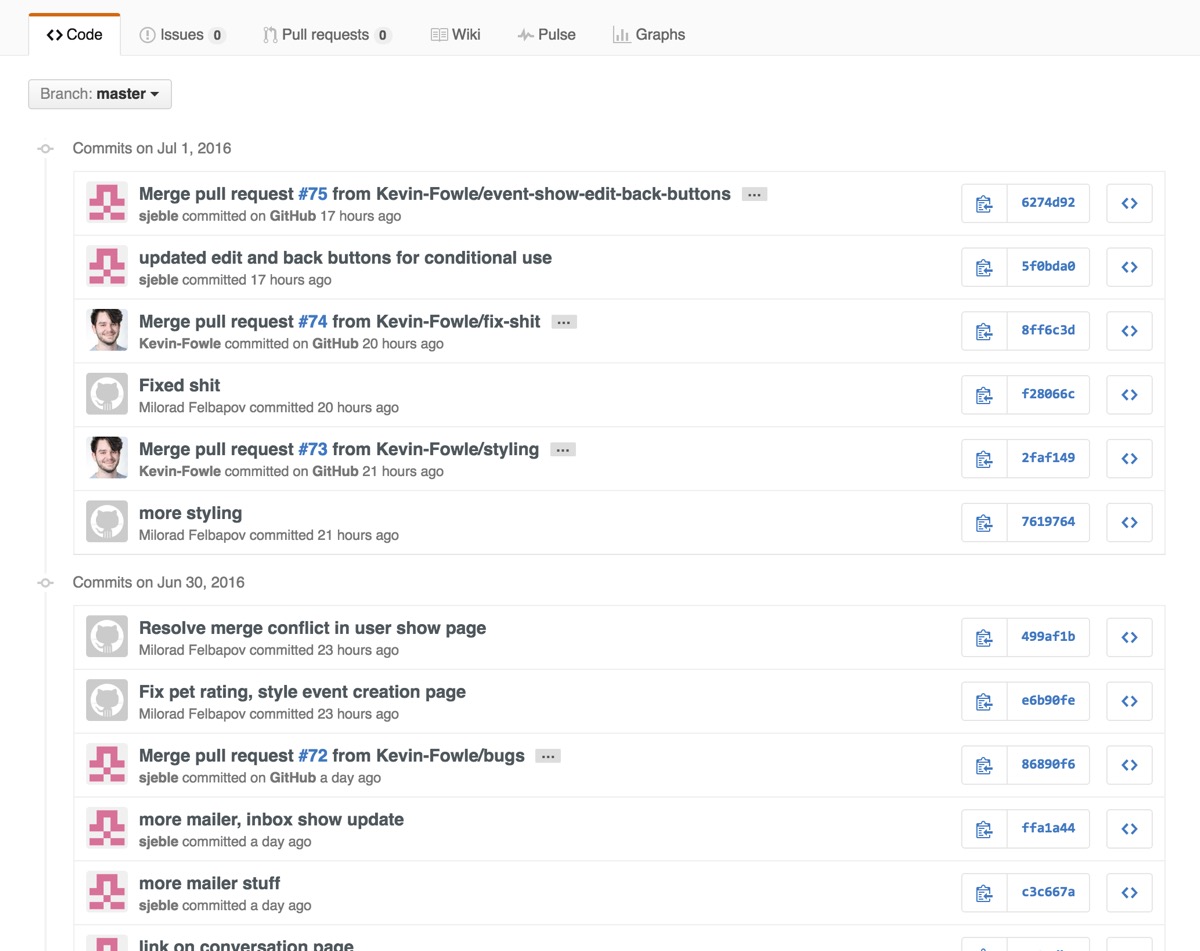
It’d be better if there wasn’t. Thing is, many people treat commit log as an actual log. A diary of theirs. They will write down their life events, current mood, messages to team members, emoticons in there.3 You’ll be reading about all the wrong paths taken, bad merges and attempts to fix them (no, you don’t want to see a visual tree of git commits in an actively developed project), and, best of all, typos. It also appears they can’t hold it, and their commit rate might approach several commits per minute. Good luck filtering the noise out.4
Which leads us to the obvious answer: Changelog! Changelog. Pause right there and think for a second. What if there was a place specifically designed to communicate what has changed between releases? A changelog. The changelog.
I like reading changelogs! It’s like opening a present. Except when it’s a new version of OS X where biggest change is a new name and rest of the stuff I don’t use anyways. What’s the point of all that effort if my trackpad would reconnect to my macbook only after a hard reboot since 10.7? At least they used to freshen up UI before.
So changelogs are a good thing. And they already exist. People are doing them, right? Except when they aren’t.
That’s what concerns me. The lack of changelogs, and the lack of discussions about the lack of changelogs. I want to make conscious decisions about my project’s dependencies. I don’t want a pig in a poke. With my luck, I can’t rely on luck either. I want to read, understand, track and evaluate every change until I’m like through 30 of them. Then I’ll blindly update rest of the libs and hope for the best anyways. But these 30, they are important. I want them to be quality changes. Is it too much to ask?
Sorry for so much ranting so far. Let me try to add some utility to this article and give an advice on good changeloggin:
Rule 1. Good changelog is not a JIRA search page.
Rule 2. Good changelog is not a commit log.
Rule 3. It’s not a commit log on Github. Did I mention that Github is terrible for that kind of stuff?
Ok, all kidding aside.
Rule 4. Put all the useful stuff in there. I know, sounds obvious, but you’d be surprised how often people don’t do that.
Rule 5. Don’t put any useless stuff in there (also see Rule 4).
Rule 6. If you move fast and break things, put breaking changes in the changelog and fix them in the next version (or not).
Rule 7. Draw in bold strokes. Give a high-level overview. Put that in changelog too.
Rule 8. Prioritize. Highlight important changes (hint: you can’t highlight every change). Do you know where you should put it?
Rule 9. Have mercy. If you put people in a complicated situation with your changes, help them out. Provide a clear migration path.
Rule 10. For controversy, explain your reasons (if you have them).
Rule 11. Don’t overwhelm the reader. Imagine they have to upgrade from three-years-old version to the latest one (because it took you three years to fix that issue). Think about them, and cross your fingers they won’t find your email address.
Rule 12. Advanced use only: give them reasons not to upgrade to that version.
Rule 13. If you forget something, so be it. It comes without warranties, right?
Rule 14. Have a changelog. This is probably the most important rule of them all. I just realized all other rules are meaningless without this one.
Rule 15. Put it in your repo. Don’t post it in user group. Well, you can, but don’t just post it in user group. Three-years-old bug, remember?
Rule 16. Call it CHANGELOG so people will know it’s important.
That’s it. Simple, right?
Dependency management software is pretty good. It is. You need to understand it (I know, totally unfair), but most of the time it gets the job done. Inside a single technology, people usually agree on version numbers, central repo, build tools—most of the technicalities.
What people don’t agree on is that every new version should come with a human-readable list of changes. Upgrading your stack shouldn’t be a blind game of luck. Maybe one day we’ll see a tool like lein ancient that will print you all the changes before asking you if you want to upgrade.5 And that list would be short, precise, well-written piece of poetry.
Not.
- Seriously, Github. Please figure that out. People try to use you for work stuff. People use versions. People need versions (except for Go folks, they gave up on them. They’re more than welcome to host on Github).↩
- Where is your semantic versioning now, huh?↩
- Nothing wrong with emoticons, of course.↩
- Did I mentioned that Github won’t show you tags on commits page? Good luck figuring out when that release happened.↩
- I know, I’m an idealist. People would never agree on a single format of anything, be it beer glass units, paper size or AC outlet. Unless it’s a cigarette lighter receptacle. Strangely enough, there’s only one standard for cigarette lighter receptacle in the world.↩
